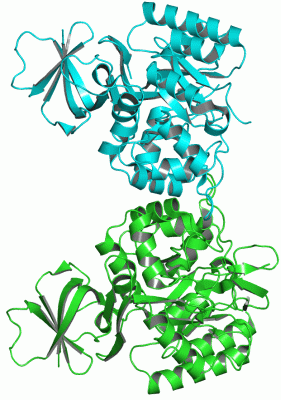
Chain A from PDB Type:PROTEIN Length:376
aligned with NAGA_ECOLI | P0AF18 from UniProtKB/Swiss-Prot Length:382
Alignment length:382
10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380
NAGA_ECOLI 1 MYALTQGRIFTGHEFLDDHAVVIADGLIKSVCPVAELPPEIEQRSLNGAILSPGFIDVQLNGCGGVQFNDTAEAVSVETLEIMQKANEKSGCTNYLPTLITTSDELMKQGVRVMREYLAKHPNQALGLHLEGPWLNLVKKGTHNPNFVRKPDAALVDFLCENADVITKVTLAPEMVPAEVISKLANAGIVVSAGHSNATLKEAKAGFRAGITFATHLYNAMPYITGREPGLAGAILDEADIYCGIIADGLHVDYANIRNAKRLKGDKLCLVTDATAPAGANIEQFIFAGKTIYYRNGLCVDENGTLSGSSLTMIEGVRNLVEHCGIALDEVLRMATLYPARAIGVEKRLGTLAAGKVANLTAFTPDFKITKTIVNGNEVVTQ 382
SCOP domains d1ymya1 A:1-53,A:351-382 d1ymya2 A:54-350 N-acetylglucosamine-6-phosphate deacetylase, NagA, catalytic domain d1ymya1 A:1-53,A:351-382 SCOP domains
CATH domains 1ymyA01 A:1-54,A:345-382 Urease, subunit C, domain 1 1ymyA02 A:55-280,A:281-344 Metal-dependent hydrolases 1ymyA02 A:55-280,A:281-344 Metal-dependent hydrolases 1ymyA01 A:1-54,A:345-382 CATH domains
Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
Sec.struct. author .eeeeeeeee....ee..eeeeee..eeeeeee........eeeeeeeeeeee.eeeeee.ee..ee........hhhhhhhhhhhhhh..eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee.......------....hhhhhhhhhhhhhh...eeeeeehhhhhhhhhhhhhhhh..eeee.....hhhhhhhhhhh...ee..............hhhhhhhhhh...eeeee......hhhhhhhhhhhhh..eeee............eeee..eeeee....eee..........hhhhhhhhhhhhh..hhhhhhhhhhhhhhhhh.hhhhhh.........eeee.....eeeeee..eeeee. Sec.struct. author
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ymy A 1 MYALTQGRIFTGHEFLDDHAVVIADGLIKSVCPVAELPPEIEQRSLNGAILSPGFIDVQLNGCGGVQFNDTAEAVSVETLEIMQKANEKSGCTNYLPTLITTSDELMKQGVRVMREYLAKHPNQALGLHLEGPWLNLV------PNFVRKPDAALVDFLCENADVITKVTLAPEMVPAEVISKLANAGIVVSAGHSNATLKEAKAGFRAGITFATHLYNAMPYITGREPGLAGAILDEADIYCGIIADGLHVDYANIRNAKRLKGDKLCLVTDATAPAGANIEQFIFAGKTIYYRNGLCVDENGTLSGSSLTMIEGVRNLVEHCGIALDEVLRMATLYPARAIGVEKRLGTLAAGKVANLTAFTPDFKITKTIVNGNEVVTQ 382
10 20 30 40 50 60 70 80 90 100 110 120 130 | - | 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380
138 145
Chain B from PDB Type:PROTEIN Length:331
aligned with NAGA_ECOLI | P0AF18 from UniProtKB/Swiss-Prot Length:382
Alignment length:382
10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 370 380
NAGA_ECOLI 1 MYALTQGRIFTGHEFLDDHAVVIADGLIKSVCPVAELPPEIEQRSLNGAILSPGFIDVQLNGCGGVQFNDTAEAVSVETLEIMQKANEKSGCTNYLPTLITTSDELMKQGVRVMREYLAKHPNQALGLHLEGPWLNLVKKGTHNPNFVRKPDAALVDFLCENADVITKVTLAPEMVPAEVISKLANAGIVVSAGHSNATLKEAKAGFRAGITFATHLYNAMPYITGREPGLAGAILDEADIYCGIIADGLHVDYANIRNAKRLKGDKLCLVTDATAPAGANIEQFIFAGKTIYYRNGLCVDENGTLSGSSLTMIEGVRNLVEHCGIALDEVLRMATLYPARAIGVEKRLGTLAAGKVANLTAFTPDFKITKTIVNGNEVVTQ 382
SCOP domains d1ymyb1 B:1-53,B:351-382 d1ymyb2 B:54-35 0 N-acetylglucosamine-6-phosphate deacetylase, NagA, catalytic d omain d1ymyb1 B:1-53,B:351-382 SCOP domains
CATH domains 1ymyB01 B:1-54,B:346-382 Urease, subunit C, domain 1 1ymyB02 B:55-3 45 Metal-dependent hydrolases 1ymyB01 B:1-54,B:346-382 CATH domains
Pfam domains (1) -------------------------------------------------Amidohydro_1-1ymyB0 1 B:50-364 ------------------ Pfam domains (1)
Pfam domains (2) -------------------------------------------------Amidohydro_1-1ymyB0 2 B:50-364 ------------------ Pfam domains (2)
Sec.struct. author .eeeeeeeee....ee..eeeeee..eeeeeee........eeeeeeeeeeee.eeeeee........-----..hhhhhhhhhhhhhh..eeeeeeeee..hhhhhhhhhhhhhhhhhhh......eeee......---------------hhhhhhhhhh...eeeeeehhhhhhhhhhhhhhhh..eeee.....hhhhhhhhhhh...ee..............hhhhhhhhhh...eeeee......hhhhhhhhhhhhh..eeee.....-------------------------------....hhhhhhhhhhhhh..hhhhhhhhhhhhhhhhh.hhhhhh.........eeee.....eeeeee..eeeee. Sec.struct. author
SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ymy B 1 MYALTQGRIFTGHEFLDDHAVVIADGLIKSVCPVAELPPEIEQRSLNGAILSPGFIDVQLNGCGGVQF-----AVSVETLEIMQKANEKSGCTNYLPTLITTSDELMKQGVRVMREYLAKHPNQALGLHLEGPWLNL---------------AALVDFLCENADVITKVTLAPEMVPAEVISKLANAGIVVSAGHSNATLKEAKAGFRAGITFATHLYNAMPYITGREPGLAGAILDEADIYCGIIADGLHVDYANIRNAKRLKGDKLCLVTDATA-------------------------------GSSLTMIEGVRNLVEHCGIALDEVLRMATLYPARAIGVEKRLGTLAAGKVANLTAFTPDFKITKTIVNGNEVVTQ 382
10 20 30 40 50 60 | - | 80 90 100 110 120 130 | - - | 160 170 180 190 200 210 220 230 240 250 260 270 | - - - 310 320 330 340 350 360 370 380
68 74 137 153 276 308
| Legend: |
|
→ Mismatch |
(orange background) |
| |
- |
→ Gap |
(green background, '-', border residues have a numbering label) |
| |
|
→ Modified Residue |
(blue background, lower-case, 'x' indicates undefined single-letter code, labelled with number + name) |
| |
x |
→ Chemical Group |
(purple background, 'x', labelled with number + name, e.g. ACE or NH2) |
| |
extra numbering lines below/above indicate numbering irregularities and modified residue names etc., number ends below/above '|' |
 Description
Description