| molecular function |
|---|
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0051019 | | mitogen-activated protein kinase binding | | Interacting selectively and non-covalently with a mitogen-activated protein kinase. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0043130 | | ubiquitin binding | | Interacting selectively and non-covalently with ubiquitin, a protein that when covalently bound to other cellular proteins marks them for proteolytic degradation. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0016236 | | macroautophagy | | The major inducible pathway for the general turnover of cytoplasmic constituents in eukaryotic cells, it is also responsible for the degradation of active cytoplasmic enzymes and organelles during nutrient starvation. Macroautophagy involves the formation of double-membrane-bounded autophagosomes which enclose the cytoplasmic constituent targeted for degradation in a membrane-bounded structure. Autophagosomes then fuse with a lysosome (or vacuole) releasing single-membrane-bounded autophagic bodies that are then degraded within the lysosome (or vacuole). Though once thought to be a purely non-selective process, it appears that some types of macroautophagy, e.g. macropexophagy, macromitophagy, may involve selective targeting of the targets to be degraded. |
| | GO:0045668 | | negative regulation of osteoblast differentiation | | Any process that stops, prevents, or reduces the frequency, rate or extent of osteoblast differentiation. |
| | GO:0051259 | | protein oligomerization | | The process of creating protein oligomers, compounds composed of a small number, usually between three and ten, of component monomers; protein oligomers may be composed of different or identical monomers. Oligomers may be formed by the polymerization of a number of monomers or the depolymerization of a large protein polymer. |
| | GO:0030500 | | regulation of bone mineralization | | Any process that modulates the frequency, rate or extent of bone mineralization. |
| | GO:0032872 | | regulation of stress-activated MAPK cascade | | Any process that modulates the frequency, rate or extent of signal transduction mediated by the stress-activated MAPK cascade. |
| cellular component |
|---|
| | GO:0031430 | | M band | | The midline of aligned thick filaments in a sarcomere; location of specific proteins that link thick filaments. Depending on muscle type the M band consists of different numbers of M lines. |
| | GO:0005776 | | autophagosome | | A double-membrane-bounded compartment that engulfs endogenous cellular material as well as invading microorganisms to target them to the vacuole/lysosome for degradation as part of macroautophagy. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0031410 | | cytoplasmic vesicle | | A vesicle found in the cytoplasm of a cell. |
| | GO:0005829 | | cytosol | | The part of the cytoplasm that does not contain organelles but which does contain other particulate matter, such as protein complexes. |
| | GO:0070062 | | extracellular exosome | | A vesicle that is released into the extracellular region by fusion of the limiting endosomal membrane of a multivesicular body with the plasma membrane. Extracellular exosomes, also simply called exosomes, have a diameter of about 40-100 nm. |
| | GO:0005770 | | late endosome | | A prelysosomal endocytic organelle differentiated from early endosomes by lower lumenal pH and different protein composition. Late endosomes are more spherical than early endosomes and are mostly juxtanuclear, being concentrated near the microtubule organizing center. |
| | GO:0005764 | | lysosome | | A small lytic vacuole that has cell cycle-independent morphology and is found in most animal cells and that contains a variety of hydrolases, most of which have their maximal activities in the pH range 5-6. The contained enzymes display latency if properly isolated. About 40 different lysosomal hydrolases are known and lysosomes have a great variety of morphologies and functions. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005739 | | mitochondrion | | A semiautonomous, self replicating organelle that occurs in varying numbers, shapes, and sizes in the cytoplasm of virtually all eukaryotic cells. It is notably the site of tissue respiration. |
| | GO:0000407 | | pre-autophagosomal structure | | Punctate structures proximal to the endoplasmic reticulum which are the sites where the Atg machinery assembles upon autophagy induction. |
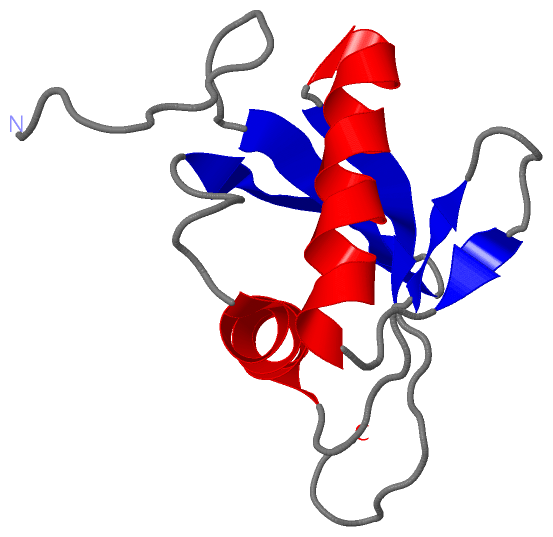
 Description
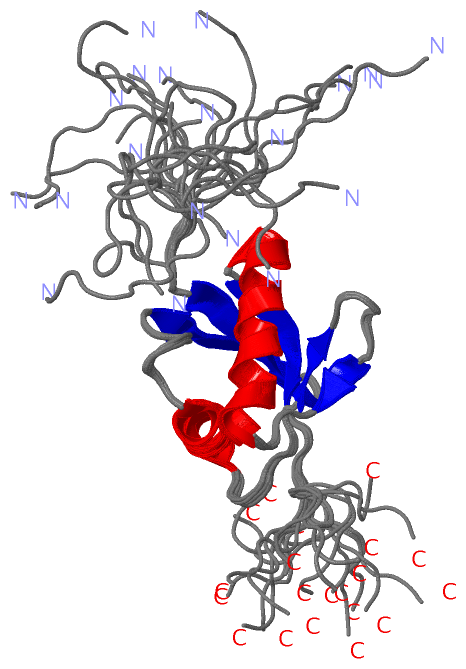
Description