|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
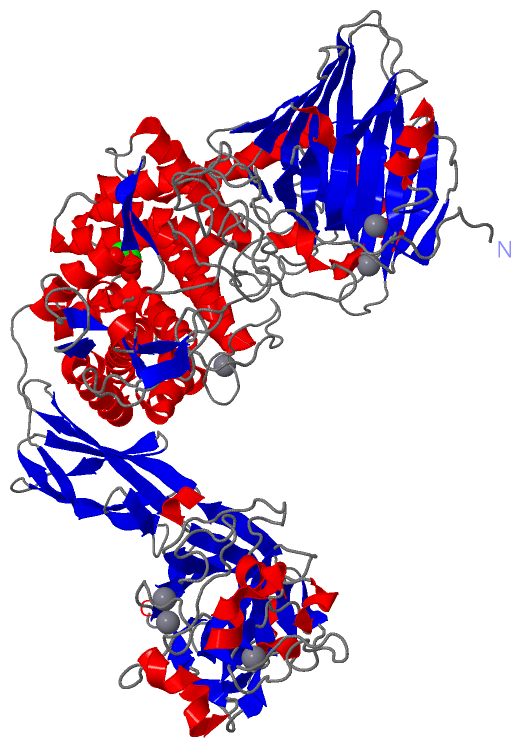
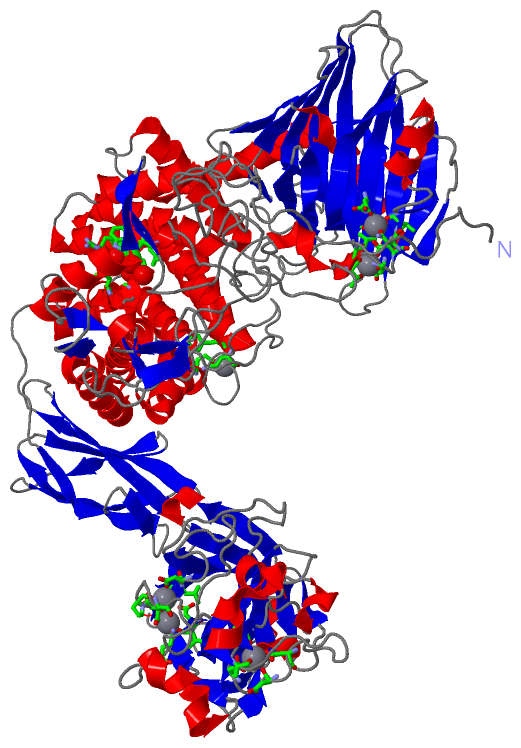
Ligands, Modified Residues, Ions (2, 7)| Asymmetric/Biological Unit (2, 7) |
Sites (7, 7)
Asymmetric Unit (7, 7)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 1UG9) |
Cis Peptide Bonds (7, 7)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1UG9) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1UG9) |
Exons (0, 0)| (no "Exon" information available for 1UG9) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:1019 aligned with Q9LBQ9_ARTGO | Q9LBQ9 from UniProtKB/TrEMBL Length:1048 Alignment length:1019 39 49 59 69 79 89 99 109 119 129 139 149 159 169 179 189 199 209 219 229 239 249 259 269 279 289 299 309 319 329 339 349 359 369 379 389 399 409 419 429 439 449 459 469 479 489 499 509 519 529 539 549 559 569 579 589 599 609 619 629 639 649 659 669 679 689 699 709 719 729 739 749 759 769 779 789 799 809 819 829 839 849 859 869 879 889 899 909 919 929 939 949 959 969 979 989 999 1009 1019 1029 1039 Q9LBQ9_ARTGO 30 TAEPPGSPGAAATWTKGDKEGVGTSLNPASKVWYTLTEGTMSEVYYPHADTPNTRELQFAVSDGTSAQRESEQTTRTVELADPKALSYRQTTTDNAGRWRLTKTYVTDPRRSTVMLGVTFEVLDGGDYQLFVLSDPSLAGTSGGDTGSVTDGALLASDLADAATPVATALVSSVGFGAVANGYVGTSDGWTDLAADGRLDNASATAGPGNISQTGQIPLAAGGKTEFSLALGFGADTAEALATAKASLGTGYKKVSKSYTGEWKKYLNSLDAPATSLTGALRTQYDVSLMTVKSHEDKTFPGAFIASLTIPWGQAASAETHREGYHAVWARDMYQSVTALLAAGDEEAAARGVEWLFTYQQQPDGHFPQTSRVDGTIGQNGIQLDETAFPILLANQIGRTDAGFYRNELKPAADYLVAAGPKTPQERWEETGGYSTSTLASQIAALAAAADIAGKNGDAGSAAVYRATADEWQRSTEKWMFTTNGPVGDGKYYLRISATGNPNDGATRDWGNGAGVHPENAVLDGGFLEFVRLGVKAPADPYVADSLAETDASISQETPGGRMWHRYTYDGYGEKADGSPWDGTGIGRLWPLLSGERGEYALANGQDALPYLETMHSAANAGYMIPEQVWDRDEPTSYGHELGRSTGSASPLSWAMAQYVRLAAGVKAGAPVETPQNVAARYAAGTPLSSPELSVTAPEALSTADSATAVVRGTTNAAKVYVSVNGTATEAPVTDGTFSLDVALTGAKNKVTVAAVAADGGTAVEDRTVLYYGSRIGALSDPAGDDNGPGTYRYPTNSAYVPGAFDLTGVDVYDAGDDYAFVATIAGEVTNPWGGQAISHQRVNIYLGKGEGGATPGLPGTNINLEHAWDSVIVTDGRFDGAGVYAPDGTRTSAVSLLAVPEARQIVTRVPKAALGGLDPATARMSVAMFGNAESGEGIGNVRPVYDGAYWEAGDPAWIKEWRFGGGAGVFDGTIPSRDTDTDDPNALDVLVGEGQTQAAVLDWRAGSPVVVPMLGLQP 1048 SCOP domains d1ug9a4 A:2-273 Glucodextranase, domain N d1ug9a1 A:274-686 Glucodextranase, domain A d1ug9a2 A:687-775 Glucodextranase, domain B d1ug9a3 A:776-1020 Glucodextranase, domain C SCOP domains CATH domains 1ug9A01 A:2-273 [code=2.70.98.10, no name defined] 1ug9A02 A:274-687 [code=1.50.10.10, no name defined] 1ug9A03 A:688-773 E-set domains of sugar-utilizing enzymes; domain 3 1ug9A04 A:774-938,A:939-1020 [code=2.60.40.1190, no name defined] 1ug9A04 A:774-938,A:939-1020 [code=2.60.40.1190, no name defined] CATH domains Pfam domains (1) ---Glucodextran_N-1ug9A04 A:5-271 ---------Glyco_hydro_15-1ug9A01 A:281-956 ---------------------------------------------------------------- Pfam domains (1) Pfam domains (2) ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Glucodextran_B-1ug9A03 A:692-775 DUF2223-1ug9A02 A:776-1018 -- Pfam domains (2) SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1ug9 A 2 TAEPPGSPGAAATWTKGDKEGVGTSLNPASKVWYTLTEGTMSEVYYPHADTPNTRELQFAVSDGTSAQRESEQTTRTVELADPKALSYRQTTTDNAGRWRLTKTYVTDPRRSTVMLGVTFEVLDGGDYQLFVLSDPSLAGTSGGDTGSVTDGALLASDLADAATPVATALVSSVGFGAVANGYVGTSDGWTDLAADGRLDNASATAGPGNISQTGQIPLAAGGKTEFSLALGFGADTAEALATAKASLGTGYKKVSKSYTGEWKKYLNSLDAPATSLTGALRTQYDVSLMTVKSHEDKTFPGAFIASLTIPWGQAASAETHREGYHAVWARDMYQSVTALLAAGDEEAAARGVEWLFTYQQQPDGHFPQTSRVDGTIGQNGIQLDETAFPILLANQIGRTDAGFYRNELKPAADYLVAAGPKTPQERWEETGGYSTSTLASQIAALAAAADIAGKNGDAGSAAVYRATADEWQRSTEKWMFTTNGPVGDGKYYLRISATGNPNDGATRDWGNGAGVHPENAVLDGGFLEFVRLGVKAPADPYVADSLAETDASISQETPGGRMWHRYTYDGYGEKADGSPWDGTGIGRLWPLLSGERGEYALANGQDALPYLETMHSAANAGYMIPEQVWDRDEPTSYGHELGRSTGSASPLSWAMAQYVRLAAGVKAGAPVETPQNVAARYAAGTPLSSPELSVTAPEALSTADSATAVVRGTTNAAKVYVSVNGTATEAPVTDGTFSLDVALTGAKNKVTVAAVAADGGTAVEDRTVLYYGSRIGALSDPAGDDNGPGTYRYPTNSAYVPGAFDLTGVDVYDAGDDYAFVATIAGEVTNPWGGQAISHQRVNIYLGKGEGGATPGLPGTNINLEHAWDSVIVTDGRFDGAGVYAPDGTRTSAVSLLAVPEARQIVTRVPKAALGGLDPATARMSVAMFGNAESGEGIGNVRPVYDGAYWEAGDPAWIKEWRFGGGAGVFDGTIPSRDTDTDDPNALDVLVGEGQTQAAVLDWRAGSPVVVPMLGLQP 1020 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 561 571 581 591 601 611 621 631 641 651 661 671 681 691 701 711 721 731 741 751 761 771 781 791 801 811 821 831 841 851 861 871 881 891 901 911 921 931 941 951 961 971 981 991 1001 1011
|
||||||||||||||||||||
SCOP Domains (4, 4)
Asymmetric/Biological Unit
 |
CATH Domains (4, 4)
Asymmetric/Biological Unit
|
Pfam Domains (4, 4)
Asymmetric/Biological Unit
|
Gene Ontology (8, 8)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A (Q9LBQ9_ARTGO | Q9LBQ9)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|