|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
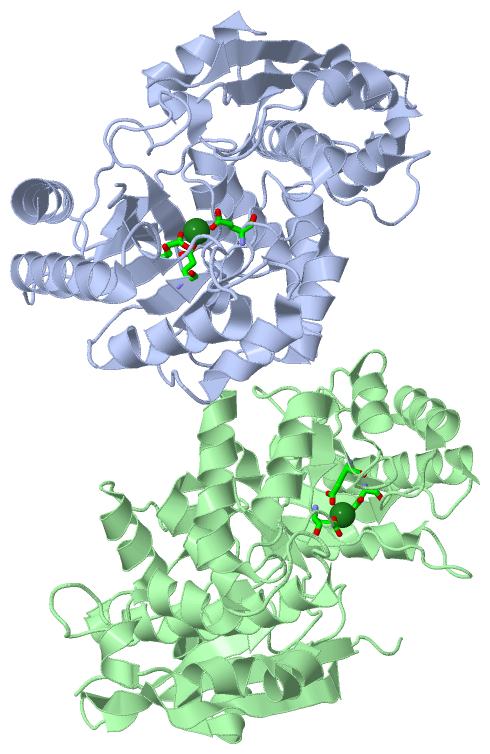
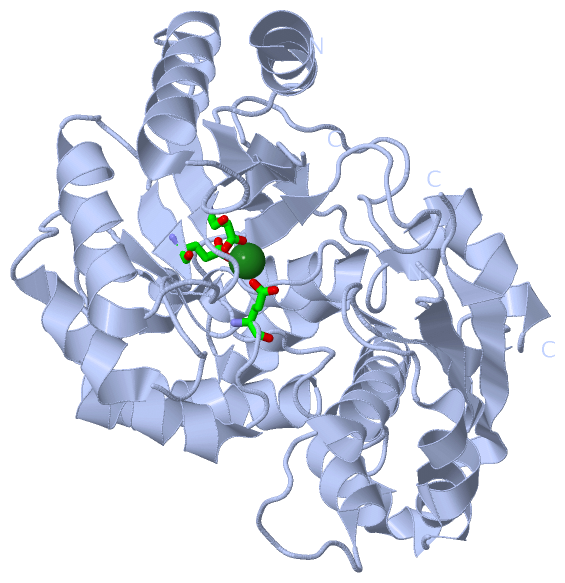
Ligands, Modified Residues, Ions (1, 2)
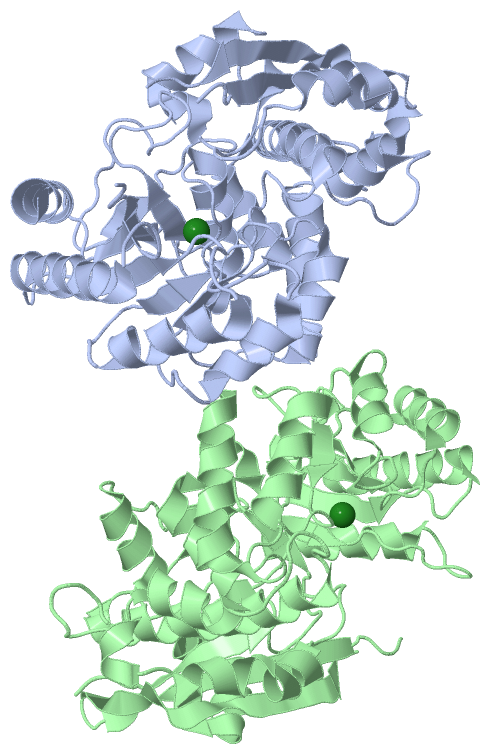
Asymmetric Unit (1, 2)
|
Sites (2, 2)
Asymmetric Unit (2, 2)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 1TZZ) |
Cis Peptide Bonds (2, 2)
Asymmetric Unit
|
||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1TZZ) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1TZZ) |
Exons (0, 0)| (no "Exon" information available for 1TZZ) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:374 aligned with TARD_BRADU | Q89FH0 from UniProtKB/Swiss-Prot Length:389 Alignment length:387 12 22 32 42 52 62 72 82 92 102 112 122 132 142 152 162 172 182 192 202 212 222 232 242 252 262 272 282 292 302 312 322 332 342 352 362 372 382 TARD_BRADU 3 VRIVDVREITKPISSPIRNAYIDFTKMTTSLVAVVTDVVREGKRVVGYGFNSNGRYGQGGLIRERFASRILEADPKKLLNEAGDNLDPDKVWAAMMINEKPGGHGERSVAVGTIDMAVWDAVAKIAGKPLFRLLAERHGVKANPRVFVYAAGGYYYPGKGLSMLRGEMRGYLDRGYNVVKMKIGGAPIEEDRMRIEAVLEEIGKDAQLAVDANGRFNLETGIAYAKMLRDYPLFWYEEVGDPLDYALQAALAEFYPGPMATGENLFSHQDARNLLRYGGMRPDRDWLQFDCALSYGLCEYQRTLEVLKTHGWSPSRCIPHGGHQMSLNIAAGLGLGGNESYPDLFQPYGGFPDGVRVENGHITMPDLPGIGFEGKSDLYKEMKALAE 389 SCOP domains d1tzza2 A:1006- 1145 Hypothetical protein Bll6730 d1tzza1 A:1146- 1392 Hypothetical protein Bll6730 SCOP domains CATH domains 1tzzA01 A:1006- 1132 Enolase-like, N-terminal domain 1tzzA02 A:1133-1392 Enolase superfamily CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1tzz A 1006 VRIVDVREITKPISS---------TKMTTSLVAVVTDVVREGKRVVGYGFNSNGRYGQGGLIRERFASRILEADPKKLLNEAGDNLDPDKVWAAMMINEKPGGHGERSVAVGTIDMAVWDAVAKIAGKPLFRLLAERHGVKANPRVFVYAAGGYY----GLSMLRGEMRGYLDRGYNVVKMKIGGAPIEEDRMRIEAVLEEIGKDAQLAVDANGRFNLETGIAYAKMLRDYPLFWYEEVGDPLDYALQAALAEFYPGPMATGENLFSHQDARNLLRYGGMRPDRDWLQFDCALSYGLCEYQRTLEVLKTHGWSPSRCIPHGGHQMSLNIAAGLGLGGNESYPDLFQPYGGFPDGVRVENGHITMPDLPGIGFEGKSDLYKEMKALAE 1392 1015 | - | 1035 1045 1055 1065 1075 1085 1095 1105 1115 1125 1135 1145 1155 | 1165 1175 1185 1195 1205 1215 1225 1235 1245 1255 1265 1275 1285 1295 1305 1315 1325 1335 1345 1355 1365 1375 1385 1020 1030 1160 1165 Chain B from PDB Type:PROTEIN Length:379 aligned with TARD_BRADU | Q89FH0 from UniProtKB/Swiss-Prot Length:389 Alignment length:388 11 21 31 41 51 61 71 81 91 101 111 121 131 141 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 TARD_BRADU 2 SVRIVDVREITKPISSPIRNAYIDFTKMTTSLVAVVTDVVREGKRVVGYGFNSNGRYGQGGLIRERFASRILEADPKKLLNEAGDNLDPDKVWAAMMINEKPGGHGERSVAVGTIDMAVWDAVAKIAGKPLFRLLAERHGVKANPRVFVYAAGGYYYPGKGLSMLRGEMRGYLDRGYNVVKMKIGGAPIEEDRMRIEAVLEEIGKDAQLAVDANGRFNLETGIAYAKMLRDYPLFWYEEVGDPLDYALQAALAEFYPGPMATGENLFSHQDARNLLRYGGMRPDRDWLQFDCALSYGLCEYQRTLEVLKTHGWSPSRCIPHGGHQMSLNIAAGLGLGGNESYPDLFQPYGGFPDGVRVENGHITMPDLPGIGFEGKSDLYKEMKALAE 389 SCOP domains d1tzzb2 B:2005-2 145 Hypothetical protein Bll6730 d1tzzb1 B:2146-2392 Hypothetical protein Bll6730 SCOP domains CATH domains 1tzzB01 B:2005-2 132 Enolase-like, N-terminal domain 1tzzB02 B:2133-2392 Enolase superfamily CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1tzz B 2005 SVRIVDVREITKPISS---------TKMTTSLVAVVTDVVREGKRVVGYGFNSNGRYGQGGLIRERFASRILEADPKKLLNEAGDNLDPDKVWAAMMINEKPGGHGERSVAVGTIDMAVWDAVAKIAGKPLFRLLAERHGVKANPRVFVYAAGGYYYPGKGLSMLRGEMRGYLDRGYNVVKMKIGGAPIEEDRMRIEAVLEEIGKDAQLAVDANGRFNLETGIAYAKMLRDYPLFWYEEVGDPLDYALQAALAEFYPGPMATGENLFSHQDARNLLRYGGMRPDRDWLQFDCALSYGLCEYQRTLEVLKTHGWSPSRCIPHGGHQMSLNIAAGLGLGGNESYPDLFQPYGGFPDGVRVENGHITMPDLPGIGFEGKSDLYKEMKALAE 2392 2014 | - |2034 2044 2054 2064 2074 2084 2094 2104 2114 2124 2134 2144 2154 2164 2174 2184 2194 2204 2214 2224 2234 2244 2254 2264 2274 2284 2294 2304 2314 2324 2334 2344 2354 2364 2374 2384 2020 2030
|
||||||||||||||||||||
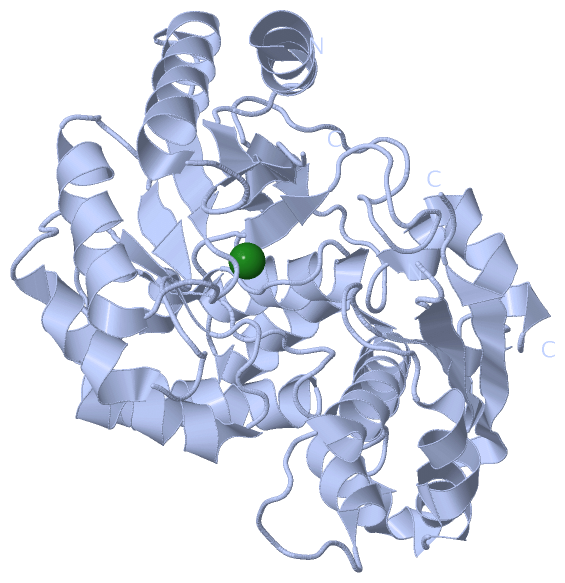
SCOP Domains (2, 4)
Asymmetric Unit
 |
CATH Domains (2, 4)
Asymmetric Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1TZZ) |
Gene Ontology (7, 7)|
Asymmetric Unit(hide GO term definitions) Chain A,B (TARD_BRADU | Q89FH0)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|