| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0008022 | | protein C-terminus binding | | Interacting selectively and non-covalently with a protein C-terminus, the end of any peptide chain at which the 1-carboxy function of a constituent amino acid is not attached in peptide linkage to another amino-acid residue. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0006259 | | DNA metabolic process | | Any cellular metabolic process involving deoxyribonucleic acid. This is one of the two main types of nucleic acid, consisting of a long, unbranched macromolecule formed from one, or more commonly, two, strands of linked deoxyribonucleotides. |
| | GO:0031100 | | animal organ regeneration | | The regrowth of a lost or destroyed animal organ. |
| | GO:0007049 | | cell cycle | | The progression of biochemical and morphological phases and events that occur in a cell during successive cell replication or nuclear replication events. Canonically, the cell cycle comprises the replication and segregation of genetic material followed by the division of the cell, but in endocycles or syncytial cells nuclear replication or nuclear division may not be followed by cell division. |
| | GO:0008283 | | cell proliferation | | The multiplication or reproduction of cells, resulting in the expansion of a cell population. |
| | GO:0034605 | | cellular response to heat | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a heat stimulus, a temperature stimulus above the optimal temperature for that organism. |
| | GO:1990705 | | cholangiocyte proliferation | | The multiplication or reproduction of cholangiocytes, resulting in the expansion of the cholangiocyte population. A cholangiocyte is an epithelial cell that is part of the bile duct. Cholangiocytes contribute to bile secretion via net release of bicarbonate and water. |
| | GO:0072574 | | hepatocyte proliferation | | The multiplication or reproduction of hepatocytes, resulting in the expansion of a cell population. Hepatocytes form the main structural component of the liver. They are specialized epithelial cells that are organized into interconnected plates called lobules. |
| | GO:0030212 | | hyaluronan metabolic process | | The chemical reactions and pathways involving hyaluronan, the naturally occurring anionic form of hyaluronic acid, any member of a group of glycosaminoglycans, the repeat units of which consist of beta-1,4 linked D-glucuronyl-beta-(1,3)-N-acetyl-D-glucosamine. |
| | GO:0014070 | | response to organic cyclic compound | | Any process that results in a change in state or activity of a cell or an organism (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of an organic cyclic compound stimulus. |
| cellular component |
|---|
| | GO:0005694 | | chromosome | | A structure composed of a very long molecule of DNA and associated proteins (e.g. histones) that carries hereditary information. |
| | GO:0000775 | | chromosome, centromeric region | | The region of a chromosome that includes the centromeric DNA and associated proteins. In monocentric chromosomes, this region corresponds to a single area of the chromosome, whereas in holocentric chromosomes, it is evenly distributed along the chromosome. |
| | GO:0000793 | | condensed chromosome | | A highly compacted molecule of DNA and associated proteins resulting in a cytologically distinct structure. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0016020 | | membrane | | A lipid bilayer along with all the proteins and protein complexes embedded in it an attached to it. |
| | GO:0005730 | | nucleolus | | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
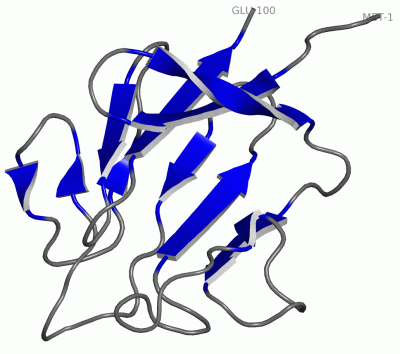
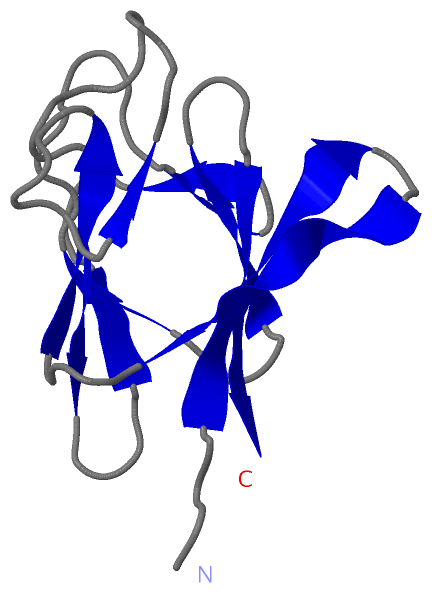
 Description
Description