| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0043140 | | ATP-dependent 3'-5' DNA helicase activity | | Catalysis of the reaction: ATP + H2O = ADP + phosphate; drives the unwinding of the DNA helix in the direction 3' to 5'. |
| | GO:0004003 | | ATP-dependent DNA helicase activity | | Catalysis of the reaction: ATP + H2O = ADP + phosphate; this reaction drives the unwinding of the DNA helix. |
| | GO:0008026 | | ATP-dependent helicase activity | | Catalysis of the reaction: ATP + H2O = ADP + phosphate, to drive the unwinding of a DNA or RNA helix. |
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0003824 | | catalytic activity | | Catalysis of a biochemical reaction at physiological temperatures. In biologically catalyzed reactions, the reactants are known as substrates, and the catalysts are naturally occurring macromolecular substances known as enzymes. Enzymes possess specific binding sites for substrates, and are usually composed wholly or largely of protein, but RNA that has catalytic activity (ribozyme) is often also regarded as enzymatic. |
| | GO:0009378 | | four-way junction helicase activity | | Catalysis of the unwinding of the DNA helix of DNA containing four-way junctions, including Holliday junctions. |
| | GO:0004386 | | helicase activity | | Catalysis of the reaction: NTP + H2O = NDP + phosphate, to drive the unwinding of a DNA or RNA helix. |
| | GO:0016787 | | hydrolase activity | | Catalysis of the hydrolysis of various bonds, e.g. C-O, C-N, C-C, phosphoric anhydride bonds, etc. Hydrolase is the systematic name for any enzyme of EC class 3. |
| | GO:0003676 | | nucleic acid binding | | Interacting selectively and non-covalently with any nucleic acid. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| biological process |
|---|
| | GO:0000729 | | DNA double-strand break processing | | The 5' to 3' exonucleolytic resection of the DNA at the site of the break to form a 3' single-strand DNA overhang. |
| | GO:0032508 | | DNA duplex unwinding | | The process in which interchain hydrogen bonds between two strands of DNA are broken or 'melted', generating a region of unpaired single strands. |
| | GO:0006310 | | DNA recombination | | Any process in which a new genotype is formed by reassortment of genes resulting in gene combinations different from those that were present in the parents. In eukaryotes genetic recombination can occur by chromosome assortment, intrachromosomal recombination, or nonreciprocal interchromosomal recombination. Intrachromosomal recombination occurs by crossing over. In bacteria it may occur by genetic transformation, conjugation, transduction, or F-duction. |
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0006265 | | DNA topological change | | The process in which a transformation is induced in the topological structure of a double-stranded DNA helix, resulting in a change in linking number. |
| | GO:0006268 | | DNA unwinding involved in DNA replication | | The process in which interchain hydrogen bonds between two strands of DNA are broken or 'melted', generating unpaired template strands for DNA replication. |
| | GO:0044237 | | cellular metabolic process | | The chemical reactions and pathways by which individual cells transform chemical substances. |
| | GO:0051276 | | chromosome organization | | A process that is carried out at the cellular level that results in the assembly, arrangement of constituent parts, or disassembly of chromosomes, structures composed of a very long molecule of DNA and associated proteins that carries hereditary information. This term covers covalent modifications at the molecular level as well as spatial relationships among the major components of a chromosome. |
| | GO:0000724 | | double-strand break repair via homologous recombination | | The error-free repair of a double-strand break in DNA in which the broken DNA molecule is repaired using homologous sequences. A strand in the broken DNA searches for a homologous region in an intact chromosome to serve as the template for DNA synthesis. The restoration of two intact DNA molecules results in the exchange, reciprocal or nonreciprocal, of genetic material between the intact DNA molecule and the broken DNA molecule. |
| | GO:0031292 | | gene conversion at mating-type locus, DNA double-strand break processing | | The 5' to 3' exonucleolytic resection of the DNA at the site of the break at the mating-type locus to form a 3' single-strand DNA overhang. |
| | GO:0031573 | | intra-S DNA damage checkpoint | | A mitotic cell cycle checkpoint that slows DNA synthesis in response to DNA damage by the prevention of new origin firing and the stabilization of slow replication fork progression. |
| | GO:0000706 | | meiotic DNA double-strand break processing | | The cell cycle process in which the 5' to 3' exonucleolytic resection of the DNA at the site of the break to form a 3' single-strand DNA overhang occurs. This takes place during meiosis. |
| | GO:0045132 | | meiotic chromosome segregation | | The process in which genetic material, in the form of chromosomes, is organized into specific structures and then physically separated and apportioned to two or more sets during M phase of the meiotic cell cycle. |
| | GO:0000070 | | mitotic sister chromatid segregation | | The cell cycle process in which replicated homologous chromosomes are organized and then physically separated and apportioned to two sets during the mitotic cell cycle. Each replicated chromosome, composed of two sister chromatids, aligns at the cell equator, paired with its homologous partner. One homolog of each morphologic type goes into each of the resulting chromosome sets. |
| | GO:0010947 | | negative regulation of meiotic joint molecule formation | | Any process that decreases the frequency, rate or extent of meiotic joint molecule formation. Meiotic joint molecule formation is the conversion of the paired broken DNA and homologous duplex DNA into a four-stranded branched intermediate, known as a joint molecule, formed during meiotic recombination. |
| | GO:0010520 | | regulation of reciprocal meiotic recombination | | Any process that modulates the frequency, rate or extent of recombination during meiosis. Reciprocal meiotic recombination is the cell cycle process in which double strand breaks are formed and repaired through a double Holliday junction intermediate. |
| | GO:0001302 | | replicative cell aging | | The process associated with progression of the cell from its inception to the end of its lifespan that occurs as the cell continues cycles of growth and division. |
| | GO:0000723 | | telomere maintenance | | Any process that contributes to the maintenance of proper telomeric length and structure by affecting and monitoring the activity of telomeric proteins, the length of telomeric DNA and the replication and repair of the DNA. These processes includes those that shorten, lengthen, replicate and repair the telomeric DNA sequences. |
| | GO:0000722 | | telomere maintenance via recombination | | Any recombinational process that contributes to the maintenance of proper telomeric length. |
| | GO:0031860 | | telomeric 3' overhang formation | | The formation of the single stranded telomeric 3' overhang, a conserved feature that ranges in length from 12 nt in budding yeast to approximately 500 nt in humans. |
| cellular component |
|---|
| | GO:0031422 | | RecQ helicase-Topo III complex | | A complex containing a RecQ family helicase and a topoisomerase III homologue; may also include one or more additional proteins; conserved from E. coli to human. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0005622 | | intracellular | | The living contents of a cell; the matter contained within (but not including) the plasma membrane, usually taken to exclude large vacuoles and masses of secretory or ingested material. In eukaryotes it includes the nucleus and cytoplasm. |
| | GO:0005730 | | nucleolus | | A small, dense body one or more of which are present in the nucleus of eukaryotic cells. It is rich in RNA and protein, is not bounded by a limiting membrane, and is not seen during mitosis. Its prime function is the transcription of the nucleolar DNA into 45S ribosomal-precursor RNA, the processing of this RNA into 5.8S, 18S, and 28S components of ribosomal RNA, and the association of these components with 5S RNA and proteins synthesized outside the nucleolus. This association results in the formation of ribonucleoprotein precursors; these pass into the cytoplasm and mature into the 40S and 60S subunits of the ribosome. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
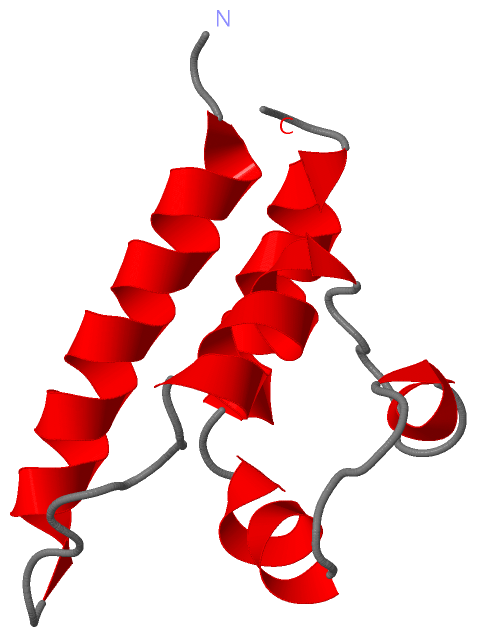
 Description
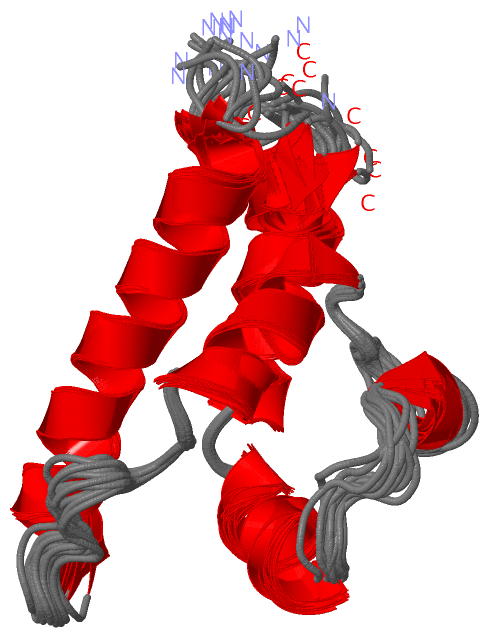
Description