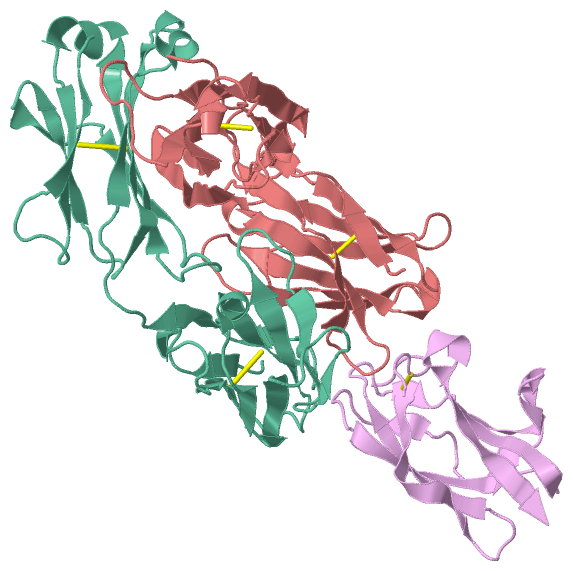
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (0, 0)| (no "Ligand,Modified Residues,Ions" information available for 1ZTX) |
Sites (0, 0)| (no "Site" information available for 1ZTX) |
SS Bonds (5, 5)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||
Cis Peptide Bonds (5, 5)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1ZTX) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1ZTX) |
Exons (0, 0)| (no "Exon" information available for 1ZTX) |
Sequences/Alignments
Asymmetric/Biological UnitChain E from PDB Type:PROTEIN Length:101 aligned with Q91KZ4_WNV | Q91KZ4 from UniProtKB/TrEMBL Length:296 Alignment length:101 200 210 220 230 240 250 260 270 280 290 Q91KZ4_WNV 191 TTYGVCSKAFKFLGTPADTGHGTVVLELQYTGTDGPCKVPISSVASLNDLTPVGRLVTVNPFVSVATANAKVLIELEPPFGDSYIVVGRGEQQINHHWHKS 291 SCOP domains d1ztxe_ E: automated matches SCOP domains CATH domains 1ztxE00 E:300-400 [code=2.60.40.350, no name defined] CATH domains Pfam domains -Flavi_glycop_C-1ztxE01 E:301-399 - Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------- Transcript 1ztx E 300 TTYGVCSKAFKFLGTPADTGHGTVVLELQYTGTDGPCKVPISSVASLNDLTPVGRLVTVNPFVSVATANAKVLIELEPPFGDSYIVVGRGEQQINHHWHKS 400 309 319 329 339 349 359 369 379 389 399
Chain H from PDB Type:PROTEIN Length:219
SCOP domains -----------------------------------------------------------------------------------------------------------------------d1ztxh1 H:114-228 Immunoglobulin heavy chain gamma constant domain 1, CH1-gamma SCOP domains
CATH domains 1ztxH01 H:1-113 Immunoglobulins 1ztxH02 H:114-228 Immunoglobulins CATH domains
Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ztx H 1 QVQLQQSGSELMKPGASVQISCKATGYTFSDYWIEWVKQRPGHGLEWIGDILCGTGRTRYNEKLKAMATFTADTSSNTAFMQLSSLTSEDSAVYYCARSASYGDYADYWGHGTTLTVSSAKTTPPSVYPLAPGCGDTTGSSVTLGCLVKGYFPESVTVTWNSGSLSSSVHTFPALLQSGLYTMSSSVTVPSSTWPSQTVTCSVAHPASSTTVDKKLEPS 228
10 20 30 40 50 | 59 69 79 ||| 86 96 || 104 114 124 ||136 146 157| 172 184 194 || || 206| 217 ||
52A 82A|| 100A| 130| 154||| 169| 180| 196| || 206| 223|
82B| 100B 133 156|| 171 183 198 || 208 226
82C 157| 200|
162 202
Chain L from PDB Type:PROTEIN Length:212
SCOP domains d1ztxl1 L:1-107 automated matches d1ztxl2 L:108-212 automated matches SCOP domains
CATH domains 1ztxL01 L:1-108 Immunoglobulins 1ztxL02 L:109-211 Immunoglobulins - CATH domains
Pfam domains -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains
SAPs(SNPs) -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs)
PROSITE -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE
Transcript -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript
1ztx L 1 DIVMTQSHKFMSTSVGDRVSITCKASQDVSTAVAWYQQKPGQSPKLLISWASTRHTGVPDRFTGSGSGTDYTLTISSVQAEDLALYYCQQHYTTPLTFGAGTKLELKRADAAPTVSIFPPSSEQLTSGGASVVCFLNNFYPKDINVKWKIDGSERQNGVLNSWTDQDSKDSTYSMSSTLTLTKDEYERHNSYTCEATHKTSTSPIVKSFNRN 212
10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210
|
||||||||||||||||||||
SCOP Domains (4, 4)
Asymmetric/Biological Unit

|
CATH Domains (2, 5)
Asymmetric/Biological Unit
|
Pfam Domains (1, 1)
Asymmetric/Biological Unit
|
Gene Ontology (38, 40)|
Asymmetric/Biological Unit(hide GO term definitions) Chain E (Q91KZ4_WNV | Q91KZ4)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|