| molecular function |
|---|
| | GO:0000384 | | first spliceosomal transesterification activity | | Catalysis of the first transesterification reaction of spliceosomal mRNA splicing. The intron branch site adenosine is the nucleophile attacking the 5' splice site, resulting in cleavage at this position. In cis splicing, this is the step that forms a lariat structure of the intron RNA, while it is still joined to the 3' exon. |
| biological process |
|---|
| | GO:0008380 | | RNA splicing | | The process of removing sections of the primary RNA transcript to remove sequences not present in the mature form of the RNA and joining the remaining sections to form the mature form of the RNA. |
| | GO:0000350 | | generation of catalytic spliceosome for second transesterification step | | Conformational rearrangement of the spliceosomal complex containing the RNA products from the 1st step of splicing to form the catalytic site for the second step of splicing. |
| | GO:0000389 | | mRNA 3'-splice site recognition | | Recognition of the intron 3'-splice site by components of the assembling U2- or U12-type spliceosome. |
| | GO:0006397 | | mRNA processing | | Any process involved in the conversion of a primary mRNA transcript into one or more mature mRNA(s) prior to translation into polypeptide. |
| cellular component |
|---|
| | GO:0000974 | | Prp19 complex | | A protein complex consisting of Prp19 and associated proteins that is involved in the transition from the precatalytic spliceosome to the activated form that catalyzes step 1 of splicing, and which remains associated with the spliceosome through the second catalytic step. It is widely conserved, found in both yeast and mammals, though the exact composition varies. In S. cerevisiae, it contains Prp19p, Ntc20p, Snt309p, Isy1p, Syf2p, Cwc2p, Prp46p, Clf1p, Cef1p, and Syf1p. |
| | GO:0071012 | | catalytic step 1 spliceosome | | A spliceosomal complex that is formed by the displacement of the two snRNPs from the precatalytic spliceosome; three snRNPs including U5 remain associated with the mRNA. This complex, sometimes called the activated spliceosome, is the catalytically active form of the spliceosome, and includes many proteins in addition to those found in the associated snRNPs. |
| | GO:0071013 | | catalytic step 2 spliceosome | | A spliceosomal complex that contains three snRNPs, including U5, bound to a splicing intermediate in which the first catalytic cleavage of the 5' splice site has occurred. The precise subunit composition differs significantly from that of the catalytic step 1, or activated, spliceosome, and includes many proteins in addition to those found in the associated snRNPs. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0071014 | | post-mRNA release spliceosomal complex | | A spliceosomal complex that is formed following the release of the spliced product from the post-spliceosomal complex and contains the excised intron and three snRNPs, including U5. |
| | GO:0071020 | | post-spliceosomal complex | | A spliceosomal complex that is formed following the second splicing event and contains the spliced product, the excised intron, and three snRNPs, including U5. |
| | GO:0005681 | | spliceosomal complex | | Any of a series of ribonucleoprotein complexes that contain snRNA(s) and small nuclear ribonucleoproteins (snRNPs), and are formed sequentially during the spliceosomal splicing of one or more substrate RNAs, and which also contain the RNA substrate(s) from the initial target RNAs of splicing, the splicing intermediate RNA(s), to the final RNA products. During cis-splicing, the initial target RNA is a single, contiguous RNA transcript, whether mRNA, snoRNA, etc., and the released products are a spliced RNA and an excised intron, generally as a lariat structure. During trans-splicing, there are two initial substrate RNAs, the spliced leader RNA and a pre-mRNA. |
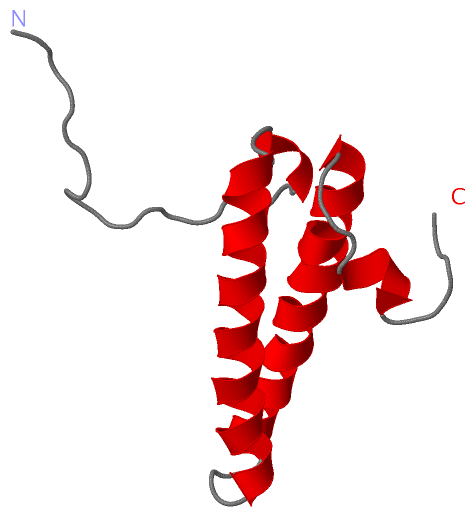
 Description
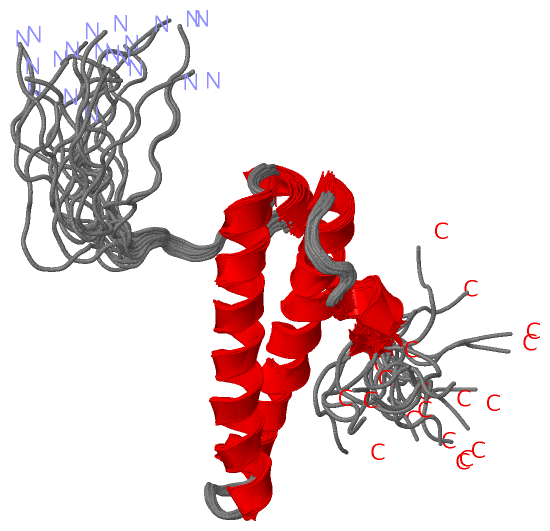
Description