|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
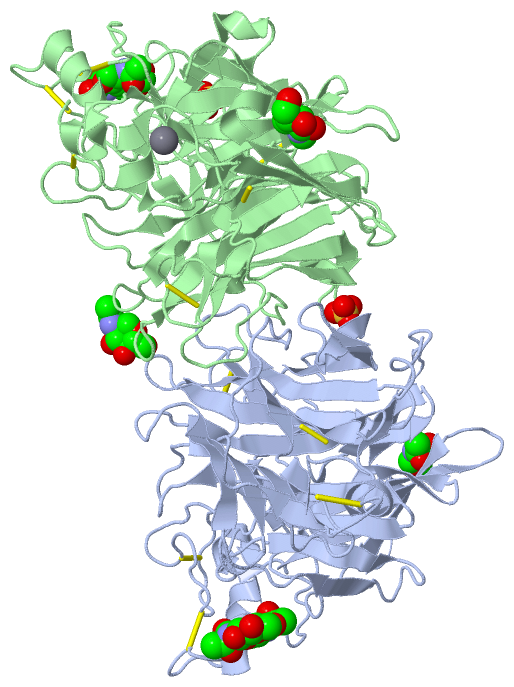
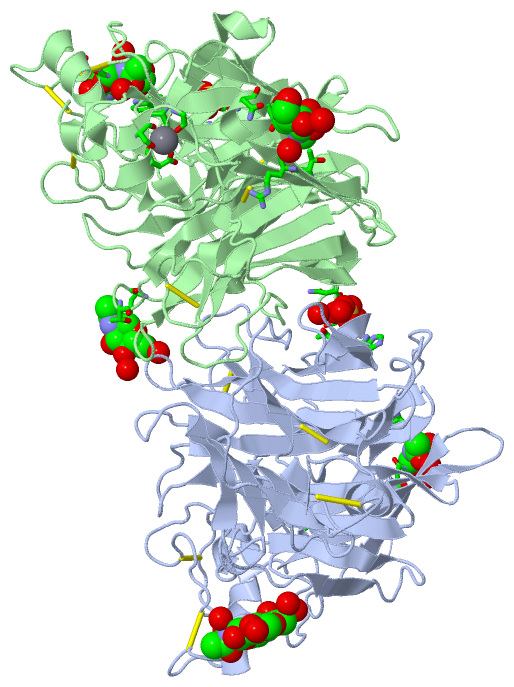
Ligands, Modified Residues, Ions (3, 11)| Asymmetric/Biological Unit (3, 11) |
Sites (11, 11)
Asymmetric Unit (11, 11)
|
SS Bonds (14, 14)
Asymmetric/Biological Unit
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Cis Peptide Bonds (2, 2)
Asymmetric/Biological Unit
|
||||||||||||
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1V3B) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1V3B) |
Exons (0, 0)| (no "Exon" information available for 1V3B) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:431 aligned with Q6WJ03_9MONO | Q6WJ03 from UniProtKB/TrEMBL Length:572 Alignment length:431 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 561 571 Q6WJ03_9MONO 142 ITHDVGIKPLNPDDFWRCTSGLPSLMKTPKIRLMPGPGLLAMPTTVDGCIRTPSLVINDLIYAYTSNLITRGCQDIGKSYQVLQIGIITVNSDLVPDLNPRISHTFNINDNRKSCSLALLNTDVYQLCSTPKVDERSDYASPGIEDIVLDIVNYDGSISTTRFKNNNISFDQPYAALYPSVGPGIYYKGKIIFLGYGGLEHPINENVICNTTGCPGKTQRDCNQASHSPWFSDRRMVNSIIVVDKGLNSIPKLKVWTISMRQNYWGSEGRLLLLGNKIYIYTRSTSWHSKLQLGIIDITDYSDIRIKWTWHNVLSRPGNNECPWGHSCPDGCITGVYTDAYPLNPTGSIVSSVILDSQKSRVNPVITYSTATERVNELAILNRTLSAGYTTTSCITHYNKGYCFHIVEINHKSLNTLQPMLFKTEIPKSCS 572 SCOP domains d1v3ba_ A: Hemagglutinin-neuraminidase glycoprotein SCOP domains CATH domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1v3b A 142 ITHDVGIKPLNPDDFWRCTSGLPSLMKTPKIRLMPGPGLLAMPTTVDGCIRTPSLVINDLIYAYTSNLITRGCQDIGKSYQVLQIGIITVNSDLVPDLNPRISHTFNINDNRKSCSLALLNTDVYQLCSTPKVDERSDYASPGIEDIVLDIVNYDGSISTTRFKNNNISFDQPYAALYPSVGPGIYYKGKIIFLGYGGLEHPINENVICNTTGCPGKTQRDCNQASHSPWFSDRRMVNSIIVVDKGLNSIPKLKVWTISMRQNYWGSEGRLLLLGNKIYIYTRSTSWHSKLQLGIIDITDYSDIRIKWTWHNVLSRPGNNECPWGHSCPDGCITGVYTDAYPLNPTGSIVSSVILDSQKSRVNPVITYSTATERVNELAILNRTLSAGYTTTSCITHYNKGYCFHIVEINHKSLNTLQPMLFKTEIPKSCS 572 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 561 571 Chain B from PDB Type:PROTEIN Length:431 aligned with Q6WJ03_9MONO | Q6WJ03 from UniProtKB/TrEMBL Length:572 Alignment length:431 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 561 571 Q6WJ03_9MONO 142 ITHDVGIKPLNPDDFWRCTSGLPSLMKTPKIRLMPGPGLLAMPTTVDGCIRTPSLVINDLIYAYTSNLITRGCQDIGKSYQVLQIGIITVNSDLVPDLNPRISHTFNINDNRKSCSLALLNTDVYQLCSTPKVDERSDYASPGIEDIVLDIVNYDGSISTTRFKNNNISFDQPYAALYPSVGPGIYYKGKIIFLGYGGLEHPINENVICNTTGCPGKTQRDCNQASHSPWFSDRRMVNSIIVVDKGLNSIPKLKVWTISMRQNYWGSEGRLLLLGNKIYIYTRSTSWHSKLQLGIIDITDYSDIRIKWTWHNVLSRPGNNECPWGHSCPDGCITGVYTDAYPLNPTGSIVSSVILDSQKSRVNPVITYSTATERVNELAILNRTLSAGYTTTSCITHYNKGYCFHIVEINHKSLNTLQPMLFKTEIPKSCS 572 SCOP domains d1v3bb_ B: Hemagglutinin-neuraminidase glycoprotein SCOP domains CATH domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- CATH domains Pfam domains ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1v3b B 142 ITHDVGIKPLNPDDFWRCTSGLPSLMKTPKIRLMPGPGLLAMPTTVDGCIRTPSLVINDLIYAYTSNLITRGCQDIGKSYQVLQIGIITVNSDLVPDLNPRISHTFNINDNRKSCSLALLNTDVYQLCSTPKVDERSDYASPGIEDIVLDIVNYDGSISTTRFKNNNISFDQPYAALYPSVGPGIYYKGKIIFLGYGGLEHPINENVICNTTGCPGKTQRDCNQASHSPWFSDRRMVNSIIVVDKGLNSIPKLKVWTISMRQNYWGSEGRLLLLGNKIYIYTRSTSWHSKLQLGIIDITDYSDIRIKWTWHNVLSRPGNNECPWGHSCPDGCITGVYTDAYPLNPTGSIVSSVILDSQKSRVNPVITYSTATERVNELAILNRTLSAGYTTTSCITHYNKGYCFHIVEINHKSLNTLQPMLFKTEIPKSCS 572 151 161 171 181 191 201 211 221 231 241 251 261 271 281 291 301 311 321 331 341 351 361 371 381 391 401 411 421 431 441 451 461 471 481 491 501 511 521 531 541 551 561 571
|
||||||||||||||||||||
SCOP Domains (1, 2)
Asymmetric/Biological Unit
 |
CATH Domains (0, 0)| (no "CATH Domain" information available for 1V3B) |
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1V3B) |
Gene Ontology (13, 13)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A,B (Q6WJ03_9MONO | Q6WJ03)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|