|
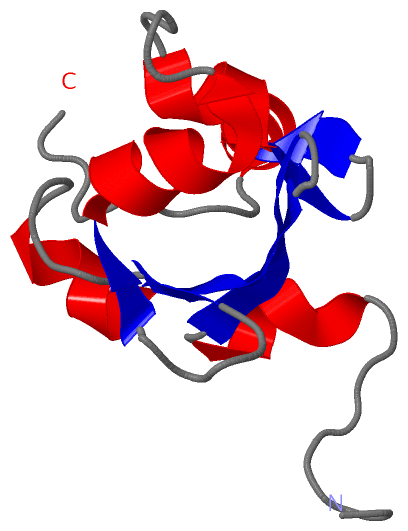
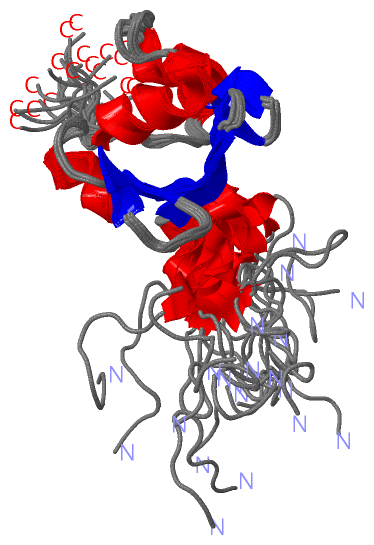
| Title | : | SOLUTION STRUCTURE OF THE SAND DOMAIN OF THE PUTATIVE NUCLEAR PROTEIN HOMOLOG (5830484A20RIK)
|
|---|
| |
|---|
| Authors | : | N. Tochio, N. Kobayashi, S. Koshiba, T. Kigawa, M. Inoue, M. Shirouzu, T. Terada, T. Yabuki, M. Aoki, E. Seki, T. Matsuda, H. Hirota, M. Yoshida, A. Tanaka, T. Osanai, Y. Matsuo, T. Arakawa, P. Carninci, J. Kawai, Y. Hayashizaki, S. Yokoyama, Riken Structural Genomics/Proteomics Initiative (Rsgi) |
|---|
| Date | : | 02 Jun 03 (Deposition) - 22 Jun 04 (Release) - 24 Feb 09 (Revision) |
|---|
| Method | : | SOLUTION NMR |
|---|
| Resolution | : | NOT APPLICABLE |
|---|
| Chains | : | NMR Structure : A (20x) |
|---|
| Keywords | : | Sand Domain, Kdwk Motif, Nuclear Protein, Structural Genomics, Riken Structural Genomics/Proteomics Initiative, Rsgi, Unknown Function (Keyword Search: [Gene Ontology, PubMed, Web (Google)] ) |
|---|
| |
|---|
| Reference | : | N. Tochio, N. Kobayashi, S. Koshiba, T. Kigawa, M. Inoue, M. Shirouzu, T. Terada, T. Yabuki, M. Aoki, E. Seki, T. Matsuda, H. Hirota, M. Yoshida, A. Tanaka, T. Osanai, Y. Matsuo, T. Arakawa, P. Carninci, J. Kawai, Y. Hayashizaki, S. Yokoyama
Solution Structure Of The Sand Domain Of The Putative Nuclear Protein Homolog (5830484A20Rik)
To Be Published |
|---|
|
 Description
Description