|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||
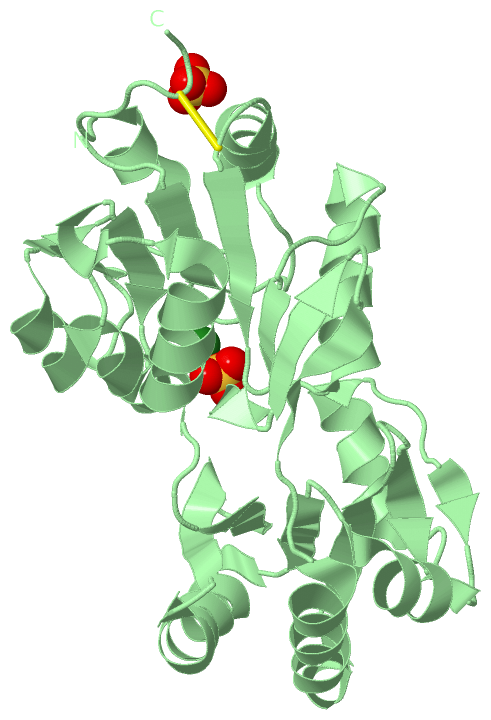
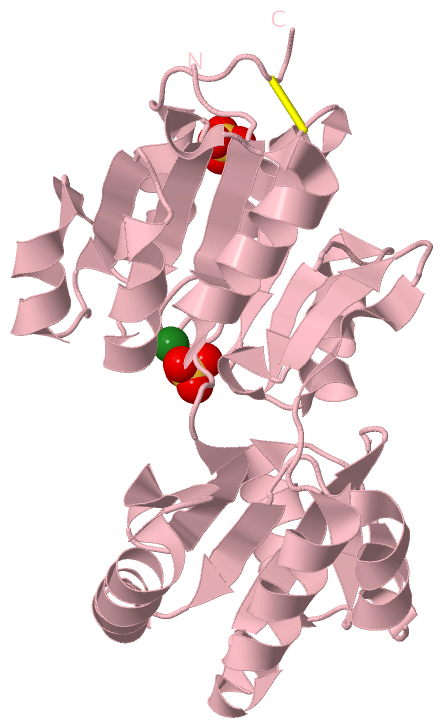
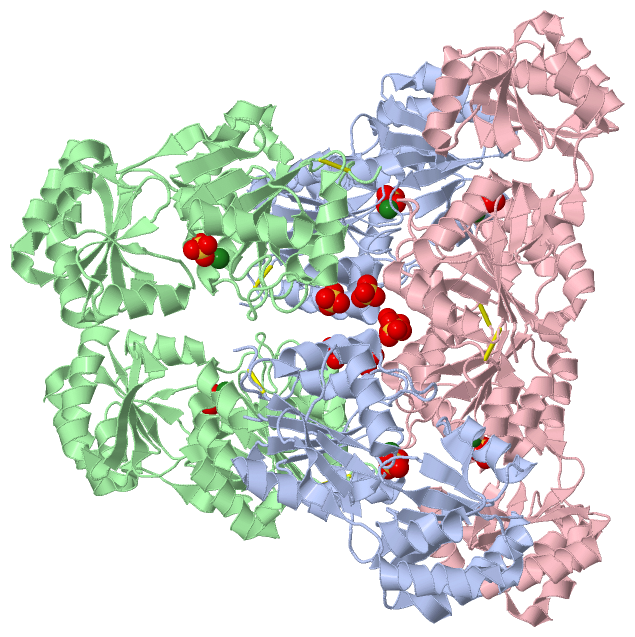
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (2, 9)| Asymmetric Unit (2, 9) Biological Unit 1 (1, 2) Biological Unit 2 (1, 2) Biological Unit 3 (1, 2) Biological Unit 4 (0, 0) |
Sites (9, 9)
Asymmetric Unit (9, 9)
|
SS Bonds (3, 3)
Asymmetric Unit
|
||||||||||||||||
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 1NF2) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1NF2) |
PROSITE Motifs (0, 0)| (no "PROSITE Motif" information available for 1NF2) |
Exons (0, 0)| (no "Exon" information available for 1NF2) |
Sequences/Alignments
Asymmetric UnitChain A from PDB Type:PROTEIN Length:267 aligned with Q9WZB9_THEMA | Q9WZB9 from UniProtKB/TrEMBL Length:268 Alignment length:267 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 Q9WZB9_THEMA 1 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 267 SCOP domains d1nf2a_ A: Hypothetical protein TM0651 SCOP domains CATH domains 1nf2A01 A:1-81,A:188-267 [code=3.40.50.1000, no name defined] 1nf2A02 A:82-187 [code=3.30.1240.10, no name defined] 1nf2A01 A:1-81,A:188-267 [code=3.40.50.1000, no name defined] CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1nf2 A 1 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 267 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 Chain B from PDB Type:PROTEIN Length:267 aligned with Q9WZB9_THEMA | Q9WZB9 from UniProtKB/TrEMBL Length:268 Alignment length:267 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 Q9WZB9_THEMA 1 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 267 SCOP domains d1nf2b_ B: Hypothetical protein TM0651 SCOP domains CATH domains 1nf2B01 B:301-381,B:488-567 [code=3.40.50.1000, no name defined] 1nf2B02 B:382-487 [code=3.30.1240.10, no name defined] 1nf2B01 B:301-381,B:488-567 [code=3.40.50.1000, no name defined] CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1nf2 B 301 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 567 310 320 330 340 350 360 370 380 390 400 410 420 430 440 450 460 470 480 490 500 510 520 530 540 550 560 Chain C from PDB Type:PROTEIN Length:267 aligned with Q9WZB9_THEMA | Q9WZB9 from UniProtKB/TrEMBL Length:268 Alignment length:267 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 Q9WZB9_THEMA 1 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 267 SCOP domains d1nf2c_ C: Hypothetical protein TM0651 SCOP domains CATH domains 1nf2C01 C:601-681,C:788-867 [code=3.40.50.1000, no name defined] 1nf2C02 C:682-787 [code=3.30.1240.10, no name defined] 1nf2C01 C:601-681,C:788-867 [code=3.40.50.1000, no name defined] CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1nf2 C 601 MYRVFVFDLDGTLLNDNLEISEKDRRNIEKLSRKCYVVFASGRMLVSTLNVEKKYFKRTFPTIAYNGAIVYLPEEGVILNEKIPPEVAKDIIEYIKPLNVHWQAYIDDVLYSEKDNEEIKSYARHSNVDYRVEPNLSELVSKMGTTKLLLIDTPERLDELKEILSERFKDVVKVFKSFPTYLEIVPKNVDKGKALRFLRERMNWKKEEIVVFGDNENDLFMFEEAGLRVAMENAIEKVKEASDIVTLTNNDSGVSYVLERISTDCLD 867 610 620 630 640 650 660 670 680 690 700 710 720 730 740 750 760 770 780 790 800 810 820 830 840 850 860
|
||||||||||||||||||||
SCOP Domains (1, 3)
Asymmetric Unit
 |
CATH Domains (2, 6)
Asymmetric Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1NF2) |
Gene Ontology (6, 6)|
Asymmetric Unit(hide GO term definitions) Chain A,B,C (Q9WZB9_THEMA | Q9WZB9)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|