| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0003824 | | catalytic activity | | Catalysis of a biochemical reaction at physiological temperatures. In biologically catalyzed reactions, the reactants are known as substrates, and the catalysts are naturally occurring macromolecular substances known as enzymes. Enzymes possess specific binding sites for substrates, and are usually composed wholly or largely of protein, but RNA that has catalytic activity (ribozyme) is often also regarded as enzymatic. |
| | GO:0016888 | | endodeoxyribonuclease activity, producing 5'-phosphomonoesters | | Catalysis of the hydrolysis of ester linkages within deoxyribonucleic acids by creating internal breaks to yield 5'-phosphomonoesters. |
| | GO:0004519 | | endonuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids by creating internal breaks. |
| | GO:0004386 | | helicase activity | | Catalysis of the reaction: NTP + H2O = NDP + phosphate, to drive the unwinding of a DNA or RNA helix. |
| | GO:0016787 | | hydrolase activity | | Catalysis of the hydrolysis of various bonds, e.g. C-O, C-N, C-C, phosphoric anhydride bonds, etc. Hydrolase is the systematic name for any enzyme of EC class 3. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0004518 | | nuclease activity | | Catalysis of the hydrolysis of ester linkages within nucleic acids. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0016779 | | nucleotidyltransferase activity | | Catalysis of the transfer of a nucleotidyl group to a reactant. |
| | GO:0005198 | | structural molecule activity | | The action of a molecule that contributes to the structural integrity of a complex or its assembly within or outside a cell. |
| | GO:0016740 | | transferase activity | | Catalysis of the transfer of a group, e.g. a methyl group, glycosyl group, acyl group, phosphorus-containing, or other groups, from one compound (generally regarded as the donor) to another compound (generally regarded as the acceptor). Transferase is the systematic name for any enzyme of EC class 2. |
| biological process |
|---|
| | GO:0006260 | | DNA replication | | The cellular metabolic process in which a cell duplicates one or more molecules of DNA. DNA replication begins when specific sequences, known as origins of replication, are recognized and bound by initiation proteins, and ends when the original DNA molecule has been completely duplicated and the copies topologically separated. The unit of replication usually corresponds to the genome of the cell, an organelle, or a virus. The template for replication can either be an existing DNA molecule or RNA. |
| | GO:0008152 | | metabolic process | | The chemical reactions and pathways, including anabolism and catabolism, by which living organisms transform chemical substances. Metabolic processes typically transform small molecules, but also include macromolecular processes such as DNA repair and replication, and protein synthesis and degradation. |
| | GO:0090305 | | nucleic acid phosphodiester bond hydrolysis | | The nucleic acid metabolic process in which the phosphodiester bonds between nucleotides are cleaved by hydrolysis. |
| | GO:0016032 | | viral process | | A multi-organism process in which a virus is a participant. The other participant is the host. Includes infection of a host cell, replication of the viral genome, and assembly of progeny virus particles. In some cases the viral genetic material may integrate into the host genome and only subsequently, under particular circumstances, 'complete' its life cycle. |
| cellular component |
|---|
| | GO:0042025 | | host cell nucleus | | A membrane-bounded organelle as it is found in the host cell in which chromosomes are housed and replicated. The host is defined as the larger of the organisms involved in a symbiotic interaction. |
| | GO:0019028 | | viral capsid | | The protein coat that surrounds the infective nucleic acid in some virus particles. It comprises numerous regularly arranged subunits, or capsomeres. |
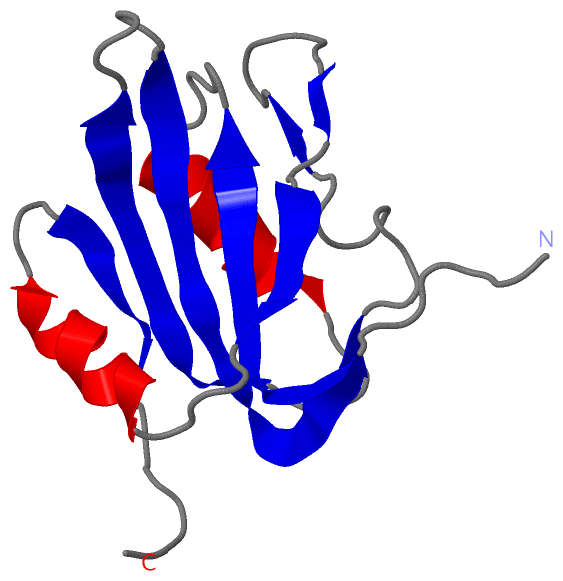
 Description
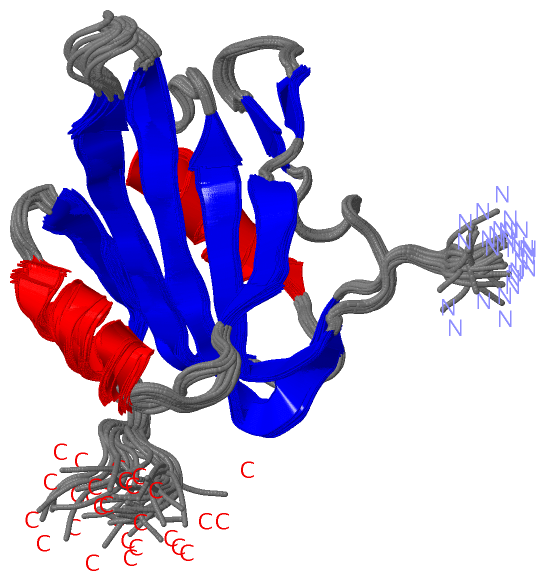
Description