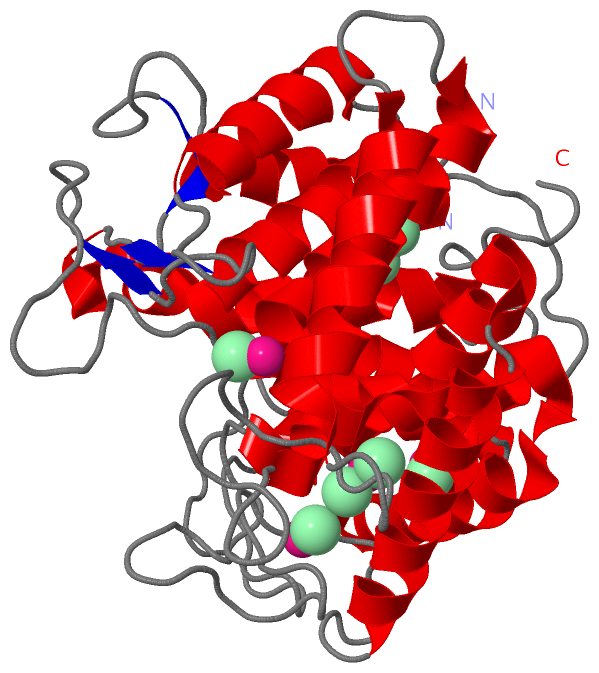
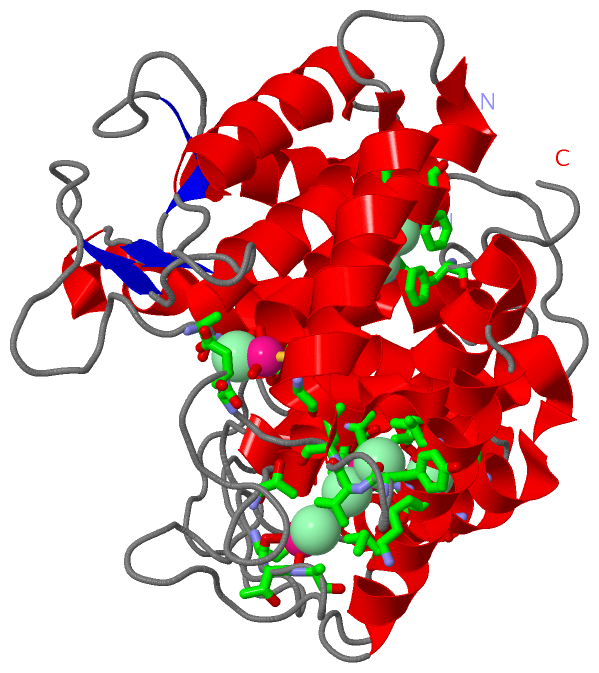
|
|
|
|
 Description
Description|
|
Compounds
|
||||||||||||||||||||||||||||||||||||
Chains, Units
Summary Information (see also Sequences/Alignments below) |
Ligands, Modified Residues, Ions (2, 13)| Asymmetric/Biological Unit (2, 13) |
Sites (13, 13)
Asymmetric Unit (13, 13)
|
SS Bonds (0, 0)| (no "SS Bond" information available for 1IS9) |
Cis Peptide Bonds (0, 0)| (no "Cis Peptide Bond" information available for 1IS9) |
SAPs(SNPs)/Variants (0, 0)| (no "SAP(SNP)/Variant" information available for 1IS9) |
PROSITE Motifs (1, 1)
Asymmetric/Biological Unit (1, 1)
|
||||||||||||||||||||||||
Exons (0, 0)| (no "Exon" information available for 1IS9) |
Sequences/Alignments
Asymmetric/Biological UnitChain A from PDB Type:PROTEIN Length:358 aligned with GUNA_CLOTH | A3DC29 from UniProtKB/Swiss-Prot Length:477 Alignment length:363 42 52 62 72 82 92 102 112 122 132 142 152 162 172 182 192 202 212 222 232 242 252 262 272 282 292 302 312 322 332 342 352 362 372 382 392 GUNA_CLOTH 33 AGVPFNTKYPYGPTSIADNQSEVTAMLKAEWEDWKSKRITSNGAGGYKRVQRDASTNYDTVSEGMGYGLLLAVCFNEQALFDDLYRYVKSHFNGNGLMHWHIDANNNVTSHDGGDGAATDADEDIALALIFADKLWGSSGAINYGQEARTLINNLYNHCVEHGSYVLKPGDRWGGSSVTNPSYFAPAWYKVYAQYTGDTRWNQVADKCYQIVEEVKKYNNGTGLVPDWCTASGTPASGQSYDYKYDATRYGWRTAVDYSWFGDQRAKANCDMLTKFFARDGAKGIVDGYTIQGSKISNNHNASFIGPVAAASMTGYDLNFAKELYRETVAVKDSEYYGYYGNSLRLLTLLYITGNFPNPLSDL 395 SCOP domains d1is9a_ A: CelA c ellulase SCOP domains CATH domains 1is9A00 A:1-363 [code=1.50.10.10, no name defined] CATH domains Pfam domains --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------GLYCOSYL_HYDROL_F8 ----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1is9 A 1 AGVPFNTKYPYGPTSIA-----VTAMLKAEWEDWKSKRITSNGAGGYKRVQRDASTNYDTVSEGMGYGLLLAVCFNEQALFDDLYRYVKSHFNGNGLMHWHIDANNNVTSHDGGDGAATDADEDIALALIFADKQWGSSGAINYGQEARTLINNLYNHCVEHGSYVLKPGDRWGGSSVTNPSYFAPAWYKVYAQYTGDTRWNQVADKCYQIVEEVKKYNNGTGLVPDWCTASGTPASGQSYDYKYDATRYGWRTAVDYSWFGDQRAKANCDMLTKFFARDGAKGIVDGYTIQGSKISNNHNASFIGPVAAASMTGYDLNFAKELYRETVAVKDSEYYGYYGNSLRLLTLLYITGNFPNPLSDL 363 10 | - | 30 40 50 60 70 80 90 100 110 120 130 140 150 160 170 180 190 200 210 220 230 240 250 260 270 280 290 300 310 320 330 340 350 360 17 23 Chain A from PDB Type:PROTEIN Length:358 aligned with GUNA_CLOTM | P0C2S2 from UniProtKB/Swiss-Prot Length:14 Alignment length:358 14 10 | - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - GUNA_CLOTM 1 AGVPFNTKTPYGPT-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- - SCOP domains d1is9a_ A: CelA cellulase SCOP domains CATH domains 1is9A00 A:1-363 [code=1.50.10.10, no name defined] CATH domains Pfam domains ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Pfam domains SAPs(SNPs) ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- SAPs(SNPs) PROSITE ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- PROSITE Transcript ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- Transcript 1is9 A 1 AGVPFNTKYPYGPTSIAVTAMLKAEWEDWKSKRITSNGAGGYKRVQRDASTNYDTVSEGMGYGLLLAVCFNEQALFDDLYRYVKSHFNGNGLMHWHIDANNNVTSHDGGDGAATDADEDIALALIFADKQWGSSGAINYGQEARTLINNLYNHCVEHGSYVLKPGDRWGGSSVTNPSYFAPAWYKVYAQYTGDTRWNQVADKCYQIVEEVKKYNNGTGLVPDWCTASGTPASGQSYDYKYDATRYGWRTAVDYSWFGDQRAKANCDMLTKFFARDGAKGIVDGYTIQGSKISNNHNASFIGPVAAASMTGYDLNFAKELYRETVAVKDSEYYGYYGNSLRLLTLLYITGNFPNPLSDL 363 10 ||25 35 45 55 65 75 85 95 105 115 125 135 145 155 165 175 185 195 205 215 225 235 245 255 265 275 285 295 305 315 325 335 345 355 17| 23
|
||||||||||||||||||||
SCOP Domains (1, 1)
Asymmetric/Biological Unit
 |
CATH Domains (1, 1)
Asymmetric/Biological Unit
|
Pfam Domains (0, 0)| (no "Pfam Domain" information available for 1IS9) |
Gene Ontology (9, 16)|
Asymmetric/Biological Unit(hide GO term definitions) Chain A (GUNA_CLOTM | P0C2S2)
Chain A (GUNA_CLOTH | A3DC29)
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Interactive Views
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Still Images
|
||||||||||||||||
Databases
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Analysis Tools
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Entries Sharing at Least One Protein Chain (UniProt ID)
Related Entries Specified in the PDB File
|
|