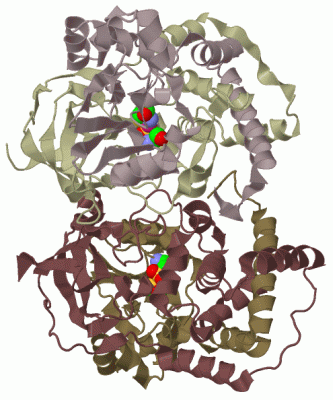
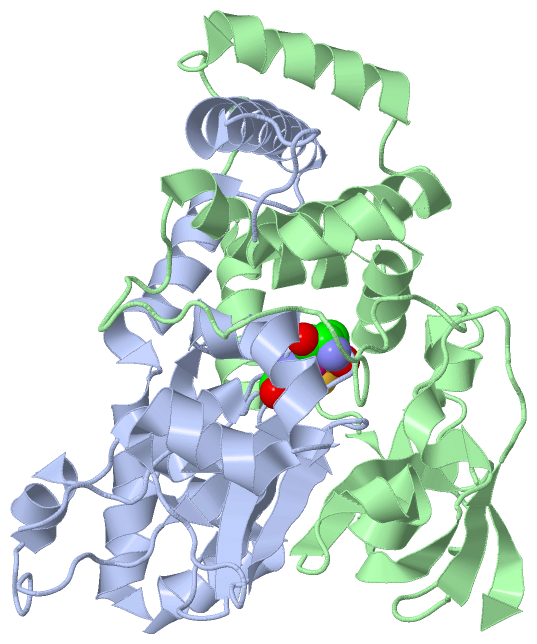
Asymmetric Unit(hide GO term definitions)
Chain A ( NHAA_PSETH | Q7SID2)
| molecular function |
|---|
| | GO:0003824 | | catalytic activity | | Catalysis of a biochemical reaction at physiological temperatures. In biologically catalyzed reactions, the reactants are known as substrates, and the catalysts are naturally occurring macromolecular substances known as enzymes. Enzymes possess specific binding sites for substrates, and are usually composed wholly or largely of protein, but RNA that has catalytic activity (ribozyme) is often also regarded as enzymatic. |
| | GO:0050897 | | cobalt ion binding | | Interacting selectively and non-covalently with a cobalt (Co) ion. |
| | GO:0080109 | | indole-3-acetonitrile nitrile hydratase activity | | Catalysis of the reaction: indole-3-acetonitrile + H2O = indole-3-acetamide. |
| | GO:0016829 | | lyase activity | | Catalysis of the cleavage of C-C, C-O, C-N and other bonds by other means than by hydrolysis or oxidation, or conversely adding a group to a double bond. They differ from other enzymes in that two substrates are involved in one reaction direction, but only one in the other direction. When acting on the single substrate, a molecule is eliminated and this generates either a new double bond or a new ring. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0018822 | | nitrile hydratase activity | | Catalysis of the reaction: an aliphatic amide = a nitrile + H2O. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046914 | | transition metal ion binding | | Interacting selectively and non-covalently with a transition metal ions; a transition metal is an element whose atom has an incomplete d-subshell of extranuclear electrons, or which gives rise to a cation or cations with an incomplete d-subshell. Transition metals often have more than one valency state. Biologically relevant transition metals include vanadium, manganese, iron, copper, cobalt, nickel, molybdenum and silver. |
| biological process |
|---|
| | GO:0050899 | | nitrile catabolic process | | The chemical reactions and pathways resulting in the breakdown of a nitrile, an organic compound containing trivalent nitrogen attached to one carbon atom. |
| | GO:0006807 | | nitrogen compound metabolic process | | The chemical reactions and pathways involving organic or inorganic compounds that contain nitrogen. |
| cellular component |
|---|
| | GO:0005575 | | cellular_component | | The part of a cell, extracellular environment or virus in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together. |
Chain B ( NHAB_PSETH | Q7SID3)
| molecular function |
|---|
| | GO:0080109 | | indole-3-acetonitrile nitrile hydratase activity | | Catalysis of the reaction: indole-3-acetonitrile + H2O = indole-3-acetamide. |
| | GO:0016829 | | lyase activity | | Catalysis of the cleavage of C-C, C-O, C-N and other bonds by other means than by hydrolysis or oxidation, or conversely adding a group to a double bond. They differ from other enzymes in that two substrates are involved in one reaction direction, but only one in the other direction. When acting on the single substrate, a molecule is eliminated and this generates either a new double bond or a new ring. |
| | GO:0018822 | | nitrile hydratase activity | | Catalysis of the reaction: an aliphatic amide = a nitrile + H2O. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0046914 | | transition metal ion binding | | Interacting selectively and non-covalently with a transition metal ions; a transition metal is an element whose atom has an incomplete d-subshell of extranuclear electrons, or which gives rise to a cation or cations with an incomplete d-subshell. Transition metals often have more than one valency state. Biologically relevant transition metals include vanadium, manganese, iron, copper, cobalt, nickel, molybdenum and silver. |
| biological process |
|---|
| | GO:0050899 | | nitrile catabolic process | | The chemical reactions and pathways resulting in the breakdown of a nitrile, an organic compound containing trivalent nitrogen attached to one carbon atom. |
| | GO:0006807 | | nitrogen compound metabolic process | | The chemical reactions and pathways involving organic or inorganic compounds that contain nitrogen. |
| cellular component |
|---|
| | GO:0005575 | | cellular_component | | The part of a cell, extracellular environment or virus in which a gene product is located. A gene product may be located in one or more parts of a cell and its location may be as specific as a particular macromolecular complex, that is, a stable, persistent association of macromolecules that function together. |
|
 Description
Description