| molecular function |
|---|
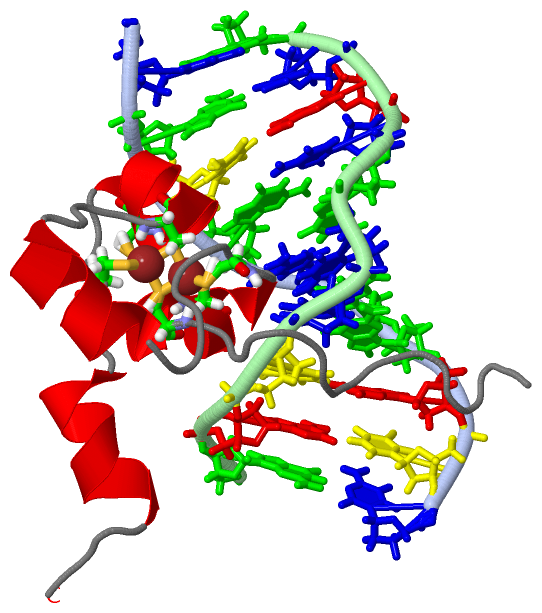
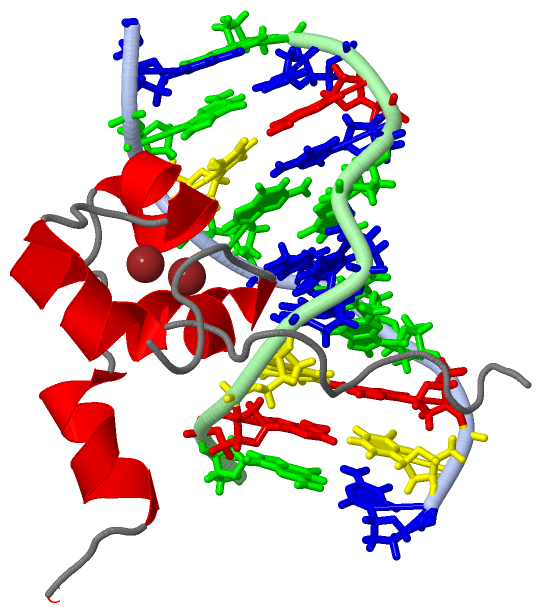
| | GO:0003677 | | DNA binding | | Any molecular function by which a gene product interacts selectively and non-covalently with DNA (deoxyribonucleic acid). |
| | GO:0000981 | | RNA polymerase II transcription factor activity, sequence-specific DNA binding | | Interacting selectively and non-covalently with a specific DNA sequence in order to modulate transcription by RNA polymerase II. The transcription factor may or may not also interact selectively with a protein or macromolecular complex. |
| | GO:0046872 | | metal ion binding | | Interacting selectively and non-covalently with any metal ion. |
| | GO:0003700 | | transcription factor activity, sequence-specific DNA binding | | Interacting selectively and non-covalently with a specific DNA sequence in order to modulate transcription. The transcription factor may or may not also interact selectively with a protein or macromolecular complex. |
| | GO:0044212 | | transcription regulatory region DNA binding | | Interacting selectively and non-covalently with a DNA region that regulates the transcription of a region of DNA, which may be a gene, cistron, or operon. Binding may occur as a sequence specific interaction or as an interaction observed only once a factor has been recruited to the DNA by other factors. |
| | GO:0008270 | | zinc ion binding | | Interacting selectively and non-covalently with zinc (Zn) ions. |
| biological process |
|---|
| | GO:0046187 | | acetaldehyde catabolic process | | The chemical reactions and pathways resulting in the breakdown of acetaldehyde, a colorless, flammable liquid intermediate in the metabolism of alcohol. |
| | GO:0006338 | | chromatin remodeling | | Dynamic structural changes to eukaryotic chromatin occurring throughout the cell division cycle. These changes range from the local changes necessary for transcriptional regulation to global changes necessary for chromosome segregation. |
| | GO:0006068 | | ethanol catabolic process | | The chemical reactions and pathways resulting in the breakdown of ethanol, CH3-CH2-OH, a colorless, water-miscible, flammable liquid produced by alcoholic fermentation. |
| | GO:0045944 | | positive regulation of transcription from RNA polymerase II promoter | | Any process that activates or increases the frequency, rate or extent of transcription from an RNA polymerase II promoter. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0006567 | | threonine catabolic process | | The chemical reactions and pathways resulting in the breakdown of threonine (2-amino-3-hydroxybutyric acid), a polar, uncharged, essential amino acid found in peptide linkage in proteins. |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| cellular component |
|---|
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
 Description
Description