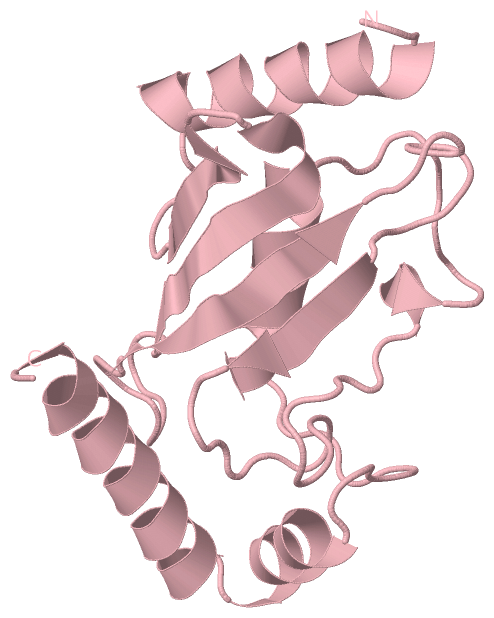
| molecular function |
|---|
| | GO:0005524 | | ATP binding | | Interacting selectively and non-covalently with ATP, adenosine 5'-triphosphate, a universally important coenzyme and enzyme regulator. |
| | GO:0000166 | | nucleotide binding | | Interacting selectively and non-covalently with a nucleotide, any compound consisting of a nucleoside that is esterified with (ortho)phosphate or an oligophosphate at any hydroxyl group on the ribose or deoxyribose. |
| | GO:0005515 | | protein binding | | Interacting selectively and non-covalently with any protein or protein complex (a complex of two or more proteins that may include other nonprotein molecules). |
| | GO:0003697 | | single-stranded DNA binding | | Interacting selectively and non-covalently with single-stranded DNA. |
| | GO:0043142 | | single-stranded DNA-dependent ATPase activity | | Catalysis of the reaction: ATP + H2O = ADP + phosphate; this reaction requires the presence of single-stranded DNA, and it drives another reaction. |
| | GO:0016740 | | transferase activity | | Catalysis of the transfer of a group, e.g. a methyl group, glycosyl group, acyl group, phosphorus-containing, or other groups, from one compound (generally regarded as the donor) to another compound (generally regarded as the acceptor). Transferase is the systematic name for any enzyme of EC class 2. |
| | GO:0061630 | | ubiquitin protein ligase activity | | Catalysis of the transfer of ubiquitin to a substrate protein via the reaction X-ubiquitin + S -> X + S-ubiquitin, where X is either an E2 or E3 enzyme, the X-ubiquitin linkage is a thioester bond, and the S-ubiquitin linkage is an amide bond: an isopeptide bond between the C-terminal glycine of ubiquitin and the epsilon-amino group of lysine residues in the substrate or, in the linear extension of ubiquitin chains, a peptide bond the between the C-terminal glycine and N-terminal methionine of ubiquitin residues. |
| | GO:0031625 | | ubiquitin protein ligase binding | | Interacting selectively and non-covalently with a ubiquitin protein ligase enzyme, any of the E3 proteins. |
| | GO:0004842 | | ubiquitin-protein transferase activity | | Catalysis of the transfer of ubiquitin from one protein to another via the reaction X-Ub + Y --> Y-Ub + X, where both X-Ub and Y-Ub are covalent linkages. |
| biological process |
|---|
| | GO:0006281 | | DNA repair | | The process of restoring DNA after damage. Genomes are subject to damage by chemical and physical agents in the environment (e.g. UV and ionizing radiations, chemical mutagens, fungal and bacterial toxins, etc.) and by free radicals or alkylating agents endogenously generated in metabolism. DNA is also damaged because of errors during its replication. A variety of different DNA repair pathways have been reported that include direct reversal, base excision repair, nucleotide excision repair, photoreactivation, bypass, double-strand break repair pathway, and mismatch repair pathway. |
| | GO:0006353 | | DNA-templated transcription, termination | | The cellular process that completes DNA-templated transcription; the formation of phosphodiester bonds ceases, the RNA-DNA hybrid dissociates, and RNA polymerase releases the DNA. |
| | GO:0006974 | | cellular response to DNA damage stimulus | | Any process that results in a change in state or activity of a cell (in terms of movement, secretion, enzyme production, gene expression, etc.) as a result of a stimulus indicating damage to its DNA from environmental insults or errors during metabolism. |
| | GO:0006348 | | chromatin silencing at telomere | | Repression of transcription of telomeric DNA by altering the structure of chromatin. |
| | GO:0000724 | | double-strand break repair via homologous recombination | | The error-free repair of a double-strand break in DNA in which the broken DNA molecule is repaired using homologous sequences. A strand in the broken DNA searches for a homologous region in an intact chromosome to serve as the template for DNA synthesis. The restoration of two intact DNA molecules results in the exchange, reciprocal or nonreciprocal, of genetic material between the intact DNA molecule and the broken DNA molecule. |
| | GO:0042275 | | error-free postreplication DNA repair | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA via processes such as template switching, which does not remove the replication-blocking lesions but does not increase the endogenous mutation rate. |
| | GO:0070987 | | error-free translesion synthesis | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication by using a specialized DNA polymerase or replication complex to insert a defined nucleotide across the lesion. This process does not remove the replication-blocking lesions but does not causes an increase in the endogenous mutation level. For S. cerevisiae, RAD30 encodes DNA polymerase eta, which incorporates two adenines. When incorporated across a thymine-thymine dimer, it does not increase the endogenous mutation level. |
| | GO:0042276 | | error-prone translesion synthesis | | The conversion of DNA-damage induced single-stranded gaps into large molecular weight DNA after replication by using a specialized DNA polymerase or replication complex to insert a defined nucleotide across the lesion. This process does not remove the replication-blocking lesions and causes an increase in the endogenous mutation level. For example, in E. coli, a low fidelity DNA polymerase, pol V, copies lesions that block replication fork progress. This produces mutations specifically targeted to DNA template damage sites, but it can also produce mutations at undamaged sites. |
| | GO:0010390 | | histone monoubiquitination | | The modification of histones by addition of a single ubiquitin group. |
| | GO:0042138 | | meiotic DNA double-strand break formation | | The cell cycle process in which double-strand breaks are generated at defined hotspots throughout the genome during meiosis I. This results in the initiation of meiotic recombination. |
| | GO:0031571 | | mitotic G1 DNA damage checkpoint | | A mitotic cell cycle checkpoint that detects and negatively regulates progression through the G1/S transition of the cell cycle in response to DNA damage. |
| | GO:0070534 | | protein K63-linked ubiquitination | | A protein ubiquitination process in which a polymer of ubiquitin, formed by linkages between lysine residues at position 63 of the ubiquitin monomers, is added to a protein. K63-linked ubiquitination does not target the substrate protein for degradation, but is involved in several pathways, notably as a signal to promote error-free DNA postreplication repair. |
| | GO:0006513 | | protein monoubiquitination | | Addition of a single ubiquitin group to a protein. |
| | GO:0000209 | | protein polyubiquitination | | Addition of multiple ubiquitin groups to a protein, forming a ubiquitin chain. |
| | GO:0016567 | | protein ubiquitination | | The process in which one or more ubiquitin groups are added to a protein. |
| | GO:0042787 | | protein ubiquitination involved in ubiquitin-dependent protein catabolic process | | The process in which a ubiquitin group, or multiple groups, are covalently attached to the target protein, thereby initiating the degradation of that protein. |
| | GO:0090089 | | regulation of dipeptide transport | | Any process that modulates the rate, frequency or extent of dipeptide transport. Dipeptide transport is the directed movement of a dipeptide, a combination of two amino acids by means of a peptide (-CO-NH-) link, into, out of or within a cell, or between cells, by means of some agent such as a transporter or pore. |
| | GO:0006355 | | regulation of transcription, DNA-templated | | Any process that modulates the frequency, rate or extent of cellular DNA-templated transcription. |
| | GO:0030435 | | sporulation resulting in formation of a cellular spore | | The process in which a relatively unspecialized cell acquires the specialized features of a cellular spore, a cell form that can be used for dissemination, for survival of adverse conditions because of its heat and dessication resistance, and/or for reproduction. |
| | GO:0000722 | | telomere maintenance via recombination | | Any recombinational process that contributes to the maintenance of proper telomeric length. |
| | GO:0006366 | | transcription from RNA polymerase II promoter | | The synthesis of RNA from a DNA template by RNA polymerase II, originating at an RNA polymerase II promoter. Includes transcription of messenger RNA (mRNA) and certain small nuclear RNAs (snRNAs). |
| | GO:0006351 | | transcription, DNA-templated | | The cellular synthesis of RNA on a template of DNA. |
| | GO:0030433 | | ubiquitin-dependent ERAD pathway | | The series of steps necessary to target endoplasmic reticulum (ER)-resident proteins for degradation by the cytoplasmic proteasome. Begins with recognition of the ER-resident protein, includes retrotranslocation (dislocation) of the protein from the ER to the cytosol, protein ubiquitination necessary for correct substrate transfer, transport of the protein to the proteasome, and ends with degradation of the protein by the cytoplasmic proteasome. |
| | GO:0071629 | | ubiquitin-dependent catabolism of misfolded proteins by cytoplasm-associated proteasome | | The chemical reactions and pathways resulting in the breakdown of misfolded proteins in the cytoplasm, which are targeted to cytoplasmic proteasomes for degradation. |
| | GO:0071596 | | ubiquitin-dependent protein catabolic process via the N-end rule pathway | | The chemical reactions and pathways resulting in the breakdown of a protein or peptide covalently tagged with ubiquitin, via the N-end rule pathway. In the N-end rule pathway, destabilizing N-terminal residues (N-degrons) in substrates are recognized by E3 ligases (N-recognins), whereupon the substrates are linked to ubiquitin and then delivered to the proteasome for degradation. |
| cellular component |
|---|
| | GO:0033503 | | HULC complex | | A ubiquitin-conjugating enzyme complex that contains two RING finger proteins, which have ubiquitin ligase activity, in addition to a protein with ubiquitin-conjugating enzyme activity; catalyzes the ubiquitination of histone H2B at lysine 119 (or the equivalent residue). In Schizosaccharomyces the subunits are Rhp1, Brl2/Rfp1 and Brl1/Rfp2. |
| | GO:1990304 | | MUB1-RAD6-UBR2 ubiquitin ligase complex | | A ubiquitin ligase complex consisting of MUB1, RAD6 and UBR2 components. It ubiquitinates, and targets for destruction, the RPN4 transcription factor, which upregulates the proteasome genes. The binding of MUB1 may position the RPN4 ubiquitylation site proximal to the Ubiquitin-RAD6 thioester and allow the transfer of Ubiquitin from RAD6 to RPN4. One of its components, MUB1, is a short-lived protein ubiquitinated by the UBR2-RAD6 ubiquitin conjugating enzyme. |
| | GO:0097505 | | Rad6-Rad18 complex | | A ubiquitin ligase complex found to be involved in post-replicative bypass of UV-damaged DNA and UV mutagenesis. In S. cerevisiae, the complex contains the ubiquitin conjugating enzyme Rad6 and Rad18, a protein containing a RING finger motif and a nucleotide binding motif. The yeast Rad6-Rad18 heterodimer has ubiquitin conjugating activity, binds single-stranded DNA, and possesses single-stranded DNA-dependent ATPase activity. |
| | GO:0000781 | | chromosome, telomeric region | | The terminal region of a linear chromosome that includes the telomeric DNA repeats and associated proteins. |
| | GO:0005737 | | cytoplasm | | All of the contents of a cell excluding the plasma membrane and nucleus, but including other subcellular structures. |
| | GO:0000790 | | nuclear chromatin | | The ordered and organized complex of DNA, protein, and sometimes RNA, that forms the chromosome in the nucleus. |
| | GO:0005634 | | nucleus | | A membrane-bounded organelle of eukaryotic cells in which chromosomes are housed and replicated. In most cells, the nucleus contains all of the cell's chromosomes except the organellar chromosomes, and is the site of RNA synthesis and processing. In some species, or in specialized cell types, RNA metabolism or DNA replication may be absent. |
| | GO:0000502 | | proteasome complex | | A large multisubunit complex which catalyzes protein degradation, found in eukaryotes, archaea and some bacteria. In eukaryotes, this complex consists of the barrel shaped proteasome core complex and one or two associated proteins or complexes that act in regulating entry into or exit from the core. |
 Description
Description